NVIDIA开源OmniVinci多模态AI模型
NVIDIA以高效多模态AI开辟新天地
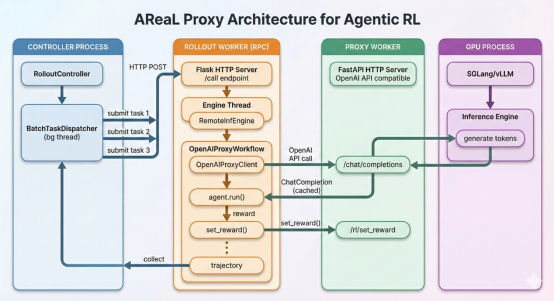
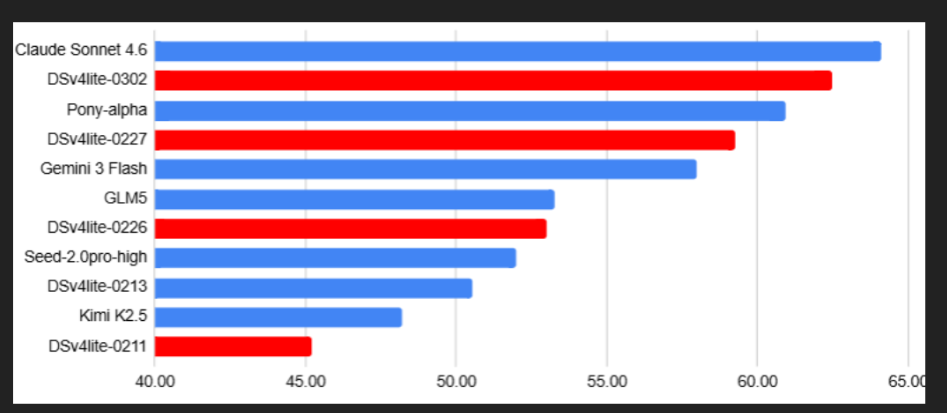
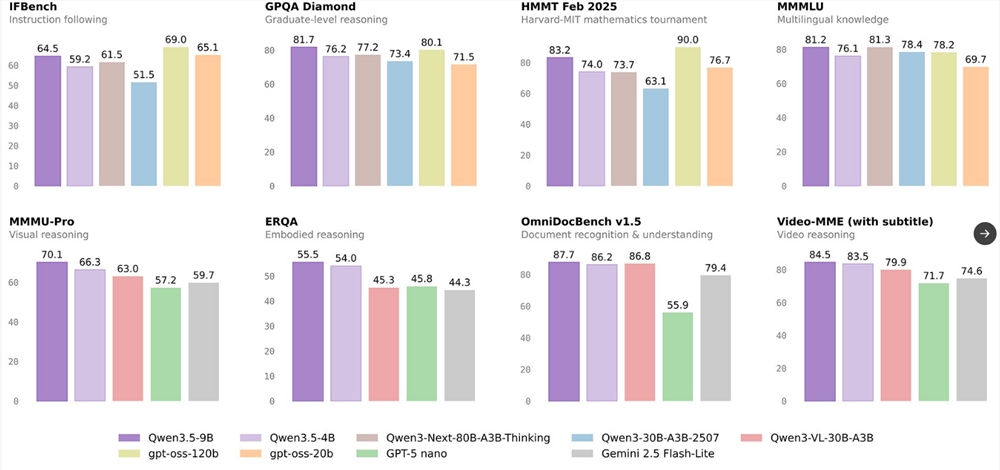
NVIDIA研究院开源了其先进的OmniVinci多模态理解模型,标志着人工智能能力的一次重大飞跃。该模型展现出惊人的效率,仅需0.2万亿训练token(而竞争对手需要1.2万亿),同时在基准测试中以19.05分的优势超越对手。
革新多模态理解
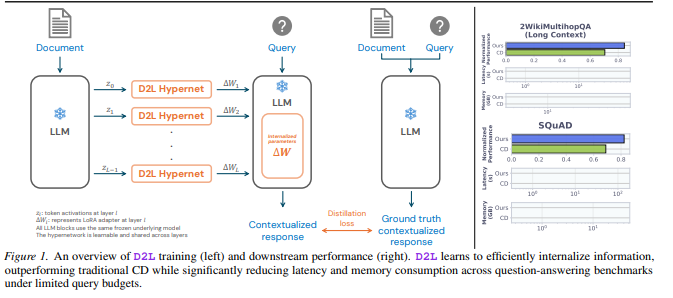
OmniVinci的核心创新在于它能同时处理和解读视觉、音频及文本信息。这一突破模拟了人类感官整合能力,使机器能形成更全面的环境认知。
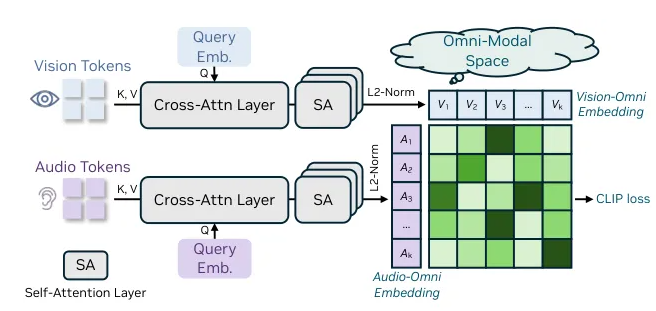
"OmniVinci代表了一种范式转变,"项目首席研究员赵亮博士解释道,"我们并非通过海量数据集暴力提升性能,而是开发了最大化学习效率的新型架构方法。"
架构突破
该模型采用多项开创性技术:
- OmniAlignNet:专用于对齐视觉与音频数据流的模块
- 时序嵌入分组:增强序列数据处理能力
- 约束旋转时序嵌入:提升时间序列理解水平
这些组件在统一的潜在空间框架内协同工作,实现在输入NVIDIA大语言模型主干前的跨模态无缝信息交换。
两阶段训练法
研究团队实施了创新的训练方案:
- 模态特定预训练:分别优化视觉、音频和文本处理路径
- 全模态联合训练:强化跨模态关联的整合学习
该方法在保持所有测试基准优异准确度的同时,带来了惊人的效率提升。
对未来AI发展的影响
OmniVinci的开源彰显了NVIDIA在推进基础AI研究的同时为全球开发者提供实用工具的承诺。行业分析师预测该技术将加速以下领域发展:
- 自主系统
- 无障碍技术
- 内容审核解决方案
- 先进人机交互界面
GitHub仓库(github.com/NVlabs/OmniVinci)已引起研究界的广泛关注。
关键要点:
🌟 相较当前顶级模型具有19.05分的基准优势
📊 六倍数据效率(0.2T vs 1.2T token)
🔑 创新架构实现卓越的多模态整合能力
🌐 开源可用性加速行业应用落地