微软研究院发布Skala:深度学习在DFT领域的重大突破
微软研究院发布Skala:深度学习在DFT领域的重大突破
微软研究院推出了Skala,这是一种新型的深度学习交换关联(XC)泛函,旨在彻底改变Kohn-Sham密度泛函理论(DFT)的计算效率。这一创新工具在精度和计算成本之间架起了桥梁,提供了混合精度水平的准确性以及半局部方法的效率。
性能与准确性
Skala在基准测试中展示了卓越的性能:
- 在W4-17分子系统上实现了1.06 kcal/mol的平均绝对误差(MAE)。
- 在单参考子集上将MAE降低至0.85 kcal/mol。
- 在GMTKN55基准测试中记录了3.89 kcal/mol的加权平均绝对偏差(WTMAD-2)。
这些结果使Skala成为顶级混合泛函的有力竞争者。
目标应用
Skala专为主族热化学计算设计,重点关注:
- 高通量反应能(ΔE)估算。
- 反应势垒预测。
- 构象和自由基稳定性排序。
- 几何结构和偶极矩计算。
该工具目前未考虑色散效应,而是依赖于固定的D3 (BJ)色散校正。
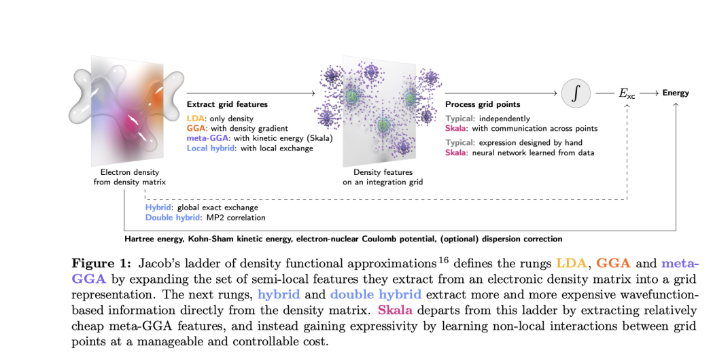
架构与训练
Skala的开发分为两个阶段:
- 预训练:利用B3LYP密度从高精度波函数能量数据中提取XC标签。
- 微调:在SCF循环中使用Skala自身的密度进行微调,无需反向传播。
该模型在一个包含约80,000个高精度总原子能(MSR-ACC/TAE)的广泛数据集上进行了训练。
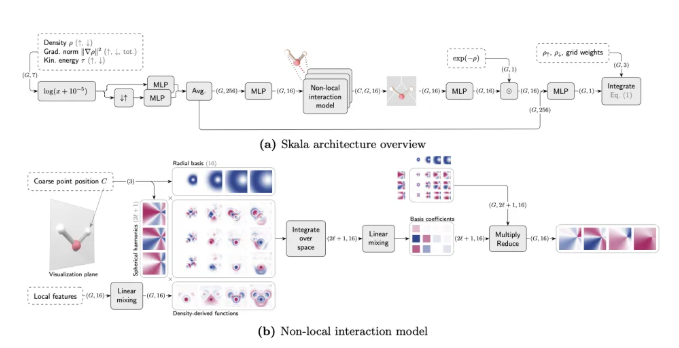
计算效率
Skala保持了O(N³)的计算复杂度,并针对GPU执行进行了优化以确保快速处理。开源代码现已在以下平台提供:
- Azure AI Foundry Laboratory
- GitHub
这种开放性使得研究人员能够使用PySCF/ASE和GauXC等平台进行高效的批量SCF计算。
关键点
🌟 高精度: Skala在特定子集上实现了低至0.85 kcal/mol的MAE值. 🛠️ 高效性: 结合了混合精度水平的准确性和半局部方法的计算成本. 🚀 开放性: 开源发布支持分子化学研究的广泛应用.