字节跳动StoryMem为AI生成视频带来一致性
字节跳动新方案让AI视频更流畅
是否注意到AI生成的视频中,角色在不同场景间经常出现外貌不一致的问题?得益于字节跳动与南洋理工大学研发的新系统StoryMem,这种令人沮丧的不连贯现象可能即将成为历史。
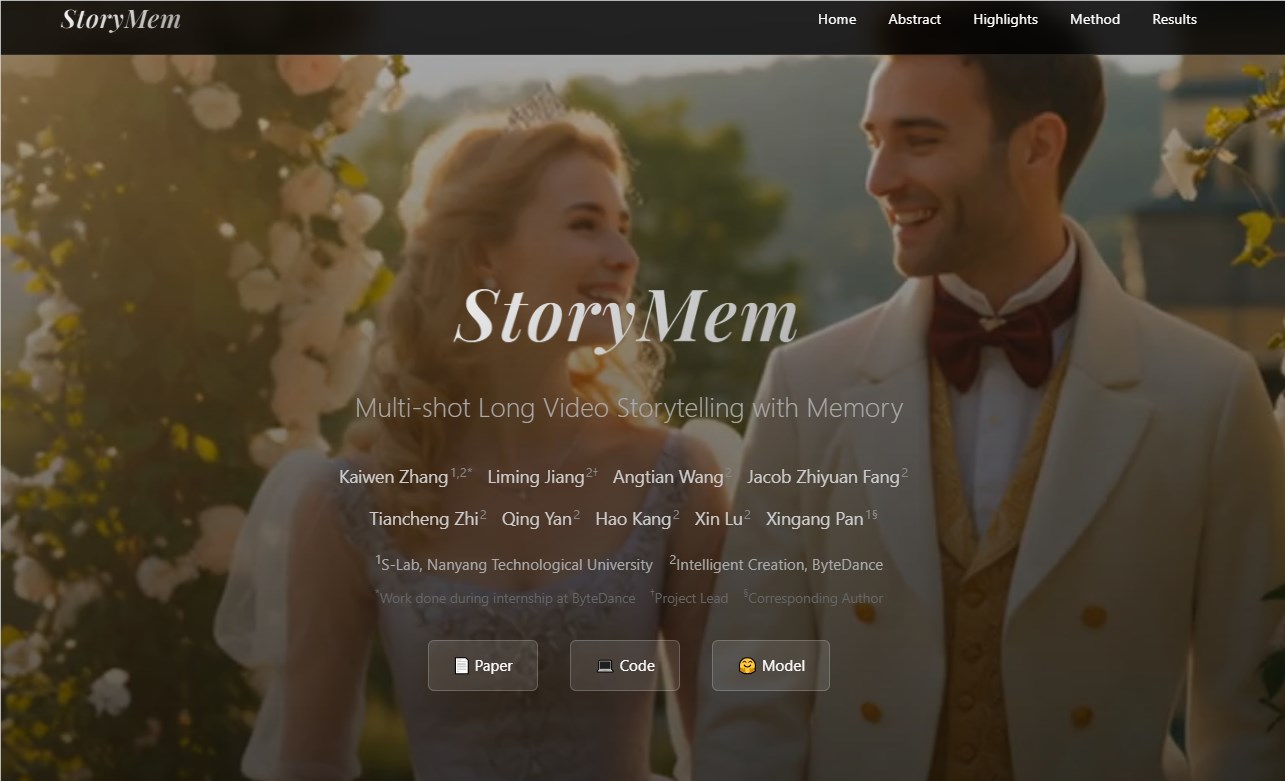
一致性挑战
Sora、Kling和Veo等主流AI视频工具擅长创作短视频片段,但将这些片段拼接成连贯叙事时往往会产生突兀的视觉变化。角色可能在镜头切换间莫名改变服装或发型,背景也会出现不可预测的变动。
"现有解决方案要么需要过量计算资源,要么牺牲连续性",StoryMem研究团队解释道:"我们想创建更智能的系统来高效保存记忆"。
StoryMem的差异化工作原理
突破点在于其选择性记忆机制:
- 智能存储生成过程中的视觉关键帧
- 引用这些记忆创建新场景时
- 通过反馈存储帧维持连续性至模型中
该方法确保生成的视频中(无论是五秒短片还是长篇内容),角色与环境始终保持可识别性。
背后的技术创新
团队使用以下要素训练StoryMem:
- 40万条视频片段(每条5秒时长)
- 基于阿里巴巴Wan2.2-I2V模型的低秩自适应(LoRA)技术
- 视觉相似性分组保持续集风格一致性
测试结果极具说服力:
- 比基础模型提升28.7%一致性
- 用户审美质量偏好得分更高
- 更强的故事连贯性表现
当前局限与未来方向
虽然取得显著进展,但StoryMem仍有不足:
- 处理多角色的复杂场景时存在困难
- 偶尔会在不同主体间错误应用视觉特征
研究人员建议在提示词中添加更清晰的角色描述可暂时缓解这些问题,同时他们正在开发更稳健的解决方案。
项目官网:https://kevin-thu.github.io/StoryMem/
核心要点:
✅ 保持AI生成视频中角色/环境跨场景一致性
📈 比现有模型提升28.7%连续性表现
🔄 采用智能帧存储与引用系统
🎬 基于40万视频片段使用LoRA技术训练
⚠️ 仍面临复杂多角色场景的处理挑战