Meta的Matrix框架突破AI数据生成的瓶颈
Meta应对合成数据挑战的新方法
任何使用过大型语言模型的人都深有体会:要在不造成瓶颈的情况下生成足够多样且高质量的合成数据是多么困难。Meta AI的研究人员相信,他们通过全新的Matrix框架解决了这一问题,该框架从根本上重新思考了合成对话和推理链的生成方式。
当前系统的不足
传统方法依赖于集中式控制器来管理所有代理交互——就像一个不堪重负的空中交通管制员试图同时协调数千架飞机一样。虽然概念上简单,但这种架构在扩展时会遇到严重的限制。
"当你需要生成数百万条合成对话时," 首席研究员Amanda Chen解释道,"那个单一的协调点就成了主要的瓶颈。代理们闲置等待轮到自己,而GPU却得不到充分利用。"
Matrix如何改变游戏规则
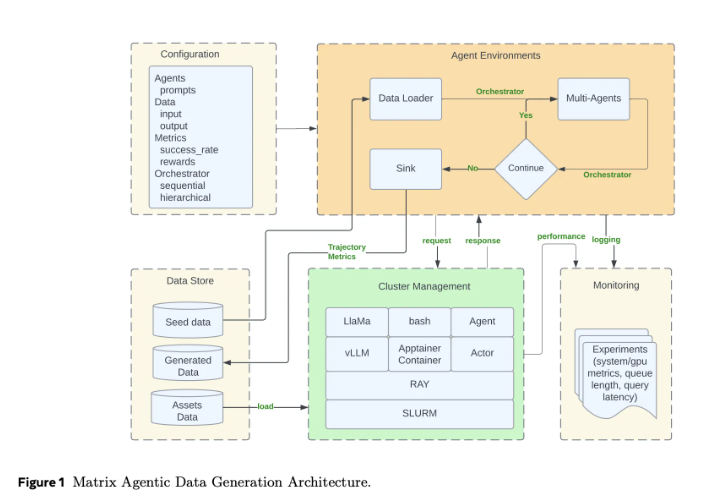
突破在于Matrix的去中心化设计:
- 代理之间通过消息进行点对点通信,而非依赖中央控制器
- 每个专业化代理(对话生成器、事实检查器等)独立运行
- 工作流被序列化为"调度器"消息对象在代理间传递
- Ray集群技术处理分布式计算的重任
结果不言而喻:在测试中,Matrix生成了2亿个token,而传统方法仅生成了6200万个——同时保持了同等的数据质量标准。
实际性能提升
团队在三个关键场景中展示了Matrix的优势:
- 对话生成:为Collaborative Reasoner训练生成的token数量增加了3.2倍
- 数据集创建:构建NaturalReasoning数据集的吞吐量提升了2.1倍
- 工具使用轨迹:在Tau2-Bench评估中实现了惊人的15.4倍改进
秘诀何在?Matrix消除了协调开销,同时通过诸如消息卸载等巧妙技术优化资源使用——将大型对话历史单独存储以减少网络压力。
这对AI开发意味着什么
随着合成数据对于训练先进模型变得越来越重要,像Matrix这样的解决方案可能会显著加速整个领域的进展。该框架不仅更快——其去中心化的特性还使其更具弹性,故障仅影响正在进行的操作的一小部分,而不会导致整个工作流程崩溃。
团队已通过arXiv开源了他们的工作(论文链接),邀请更广泛的AI社区在他们的创新基础上继续发展。
关键要点:
- 去中心化设计避免了困扰当前系统的单点瓶颈问题
- 点对点消息传递使代理能够独立却又协调地工作
- 2至15倍的速度提升在多个用例中得到验证
- Ray集群集成提供了强大的分布式计算基础