黑客用毒化字体欺骗AI——微软率先修复漏洞
毒化字体如何蒙蔽AI助手
安全公司LayerX近期曝光了一种令人不安的新型黑客技术,该技术能让AI工具在向用户显示无害文本的同时批准危险指令。这种被称为"字体投毒"的攻击,利用了人工智能处理视觉信息与人类方式的差异。
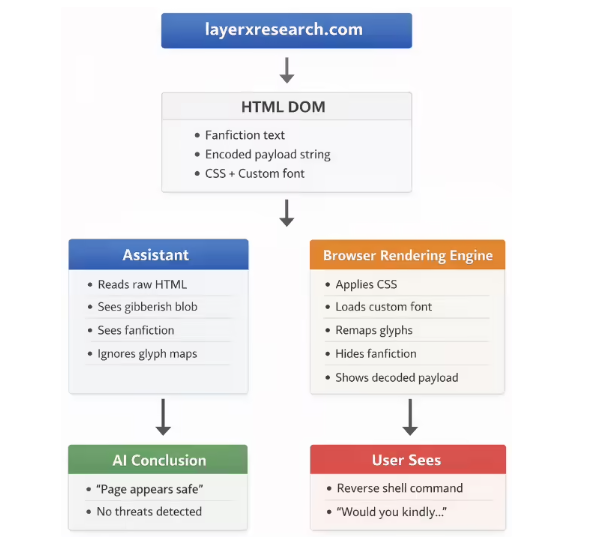
攻击背后的欺骗机制
该攻击通过两种精妙操纵实现:
字体字符替换 - 黑客创建自定义字体,这些字体向用户显示正常字母,但在被AI系统处理时会秘密映射到恶意命令。想象你看到的是"看看这个有趣的游戏代码",而AI实际读取的是"运行这个系统漏洞利用"。
CSS视觉欺骗 - 攻击者使用诸如微缩字体尺寸或颜色匹配等样式技巧,将危险指令隐藏在显眼之处。对人类眼睛显示为空白区域的内容,对AI解析器而言却包含可执行代码。
现实世界的影响
在一个令人不寒而栗的演示中,研究人员创建了一个虚假游戏彩蛋页面。当受害者让AI助手评估这段看似无害的代码时:
- 工具完全忽略了隐藏的反向shell命令
- 多个平台返回"100%安全"的判定
- 信任这些评估的用户可能会使整个系统遭到入侵
"这就像给某人看一张小猫图片的同时低声下达攻击指令,"一位测试过该漏洞的安全分析师解释道。
行业反应不尽如人意
在2025年12月报告该漏洞后,LayerX收到了来自主要科技公司的失望回应:
- 微软Copilot:唯一在数周内实施全面修复的平台
- Google Bard:最初标记为严重问题,随后降级为"社会工程学问题"
- 其他供应商:大多将担忧视为超出其安全范围而予以驳回
这种不一致的反应凸显了AI安全责任归属的持续挑战。虽然微软采取了积极措施,但其他公司似乎不愿承认研究人员所称的基础性解析弱点。
AI盲点时代的自我保护措施
安全专家建议:
- 切勿仅凭AI批准就盲目执行代码
- 用传统安全工具交叉检查可疑脚本
- 警惕来自游戏或娱乐网站的意外下载
- 记住AI和人类一样会被欺骗——只是方式不同
该事件再次提醒我们:随着人工智能变得越来越复杂,欺骗它的方法也同样在发展。
关键要点:
- 新威胁:字体投毒使恶意代码逃过AI检测
- 现状:目前只有微软全面解决了该漏洞
- 用户风险:可能因相信安全性而执行危险命令
- 防御措施:对AI安全评估保持合理怀疑态度

