GPT-4输出通过自优化方法提升20%,无需额外训练
人工智能领域的一项突破性进展——Self-Refine方法展示了像GPT-4这样的大型语言模型(LLM)如何在不进行额外训练的情况下显著提升自身输出质量。这种创新方法通过自主自我批评和迭代优化,实现了约20%的性能提升。
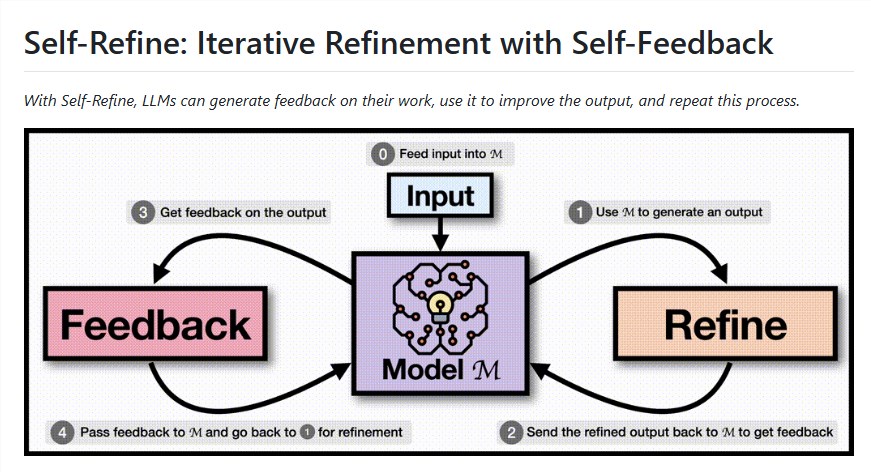
Self-Refine工作原理 该系统通过三步循环运作:
- 初始响应生成:模型根据输入提示产生首次输出
- 自我评估:AI批判性评估自身工作,识别改进领域
- 优化:利用反馈意见,模型持续优化输出直至达到质量标准
研究人员发现该方法对GPT-4等先进模型特别有效,在七项不同任务中平均提升了20%的性能。在代码可读性等特定应用中,改进幅度高达40%。Self-Refine的卓越之处在于其简洁性——它不需要新的训练数据或外部工具,只需精心设计的提示词。
实际应用前景广阔 该技术已在多个领域展现出令人印象深刻的成果:
- 代码优化:GPT-4的编码性能提升8.7个单位,可读性提高13.9个单位
- 对话式AI:初始对话输出仅25%的人类偏好率经优化后升至75%
- 内容创作:故事生成在逻辑流畅性和吸引力方面获得21.6个单位的质量提升
Self-Refine的开源特性(https://github.com/ag-ui-protocol/ag-ui)降低了开发者实施这些改进的门槛。但该系统也存在局限——基础较弱的模型难以生成有效的自我反馈,且迭代过程可能增加计算成本。
行业背景与未来方向 Self-Refine进入了自改进AI系统的竞争领域。与依赖外部工具或额外训练数据的方法不同,该技术因其简洁性和通用性脱颖而出。早期采用者报告称,在资源受限无法添加外部组件的环境中尤其有价值。
这项技术代表了向更自主的AI系统迈出的重要一步,这些系统能够进行自我评估和改进。未来发展可能会将Self-Refine扩展到图像和语音生成等多模态应用,或与思维链推理等其他技术结合使用。
与任何新兴技术一样,确保反馈质量的一致性和管理计算开销(特别是实时应用)仍是挑战。开源社区正持续完善这些方面并探索新的应用场景。
关键要点
- Self-Refine无需额外训练即可将LLM输出提升约20%
- 该方法通过单一模型内的生成-反馈-优化循环运作
- GPT-4等先进模型效果最佳;较弱模型难以实现有效自我反馈
- 应用范围涵盖代码优化、对话系统和内容创作
- 计算成本和反馈一致性仍是主要挑战




