Google Magika 1.0:基于Rust的文件检测技术飞跃
Google通过Magika 1.0将文件检测推向新高度
面向开发者和安全专业人士的重大更新中,Google推出了其AI文件类型检测系统的稳定版Magika 1.0。该版本的特别之处在于完全基于Rust架构重构,将速度和安全性置于文件识别的核心位置。
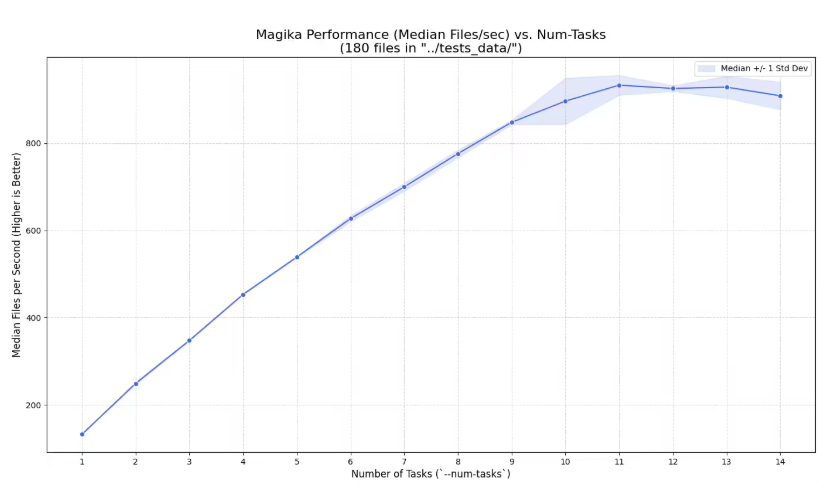
令人瞩目的性能表现
数据说明一切:Magika现在单核处理器上每秒可识别数百个文件。扩展到多核系统后,每秒可处理数千个文件。这种速度得益于两项核心技术——处理模型推理的ONNX Runtime和管理异步处理的Tokio框架。
扩展的格式支持
自初版发布以来,支持的文件格式数量几乎翻倍,现已覆盖200多种类型。本次更新特别增加了对以下类型的支持:
- 数据科学格式如Jupyter Notebooks和PyTorch文件
- 现代编程语言包括Swift和TypeScript
- DevOps工具及数据库文件如SQLite
- 设计文件包含AutoCAD格式
系统还能更智能地区分相似文件——比如C与C++代码或JavaScript与TypeScript的识别准确率达到历史新高。
技术内幕:解决训练难题
实现这些功能并非一帆风顺。Google工程师面临两大挑战:所需训练数据的庞大体量,以及某些文件类型的样本稀缺问题。他们的解决方案是结合定制数据集库SedPack与Google自研生成式AI工具Gemini创建的合成训练数据。
"我们的模型不仅要理解常见文件,还要识别冷门格式",Google发言人解释道,"真实数据与高质量合成样本的结合让我们具备了这种优势"。
开发者友好改进
本次升级不仅关乎性能提升——Google还使Magika更易使用:
- 更新的Python和TypeScript模块简化集成流程
- 跨操作系统仅需几条简单命令即可完成安装
- Google积极鼓励社区贡献以持续优化工具
自去年开源以来月下载量超百万次的数据表明,Magika的热度持续攀升。这个最新版本使其成为处理多样化文件类型的开发者更加不可或缺的工具。
核心亮点速览
- Rust基础架构同时提升速度和内存安全性
- 支持200+种格式包含专业数据科学和编程文件
- 通过更新语言模块简化集成
- 鼓励开源参与的社区驱动开发