Google DeepMind的D4RT赋予AI穿越时空的视觉能力
Google DeepMind突破四维AI视觉新纪元

数十年来,让机器像人类一样观察始终是计算机视觉领域的重大挑战。虽然相机赋予了AI眼睛,但真正的理解力——即解读当前场景并预判未来运动的能力——一直困扰着研究人员。得益于Google DeepMind的最新创新D4RT(动态四维重建与追踪),这道屏障或许终将被打破。
超越画面框架的视觉
新系统代表了机器感知视觉信息的根本性变革。传统方法需要拼接多个专用模型——一个用于深度计算,另一个用于运动追踪,还有其他用于视角分析。"这就像蒙着眼睛玩拼图",未参与该项目的计算机视觉专家Elena Vasquez博士解释道。
D4RT用基于单一核心问题的优雅方案取代了这种拼凑方法:"这个像素在三维空间中的此刻位置是什么?"这种查询式架构让系统能以空前效率重建动态场景。
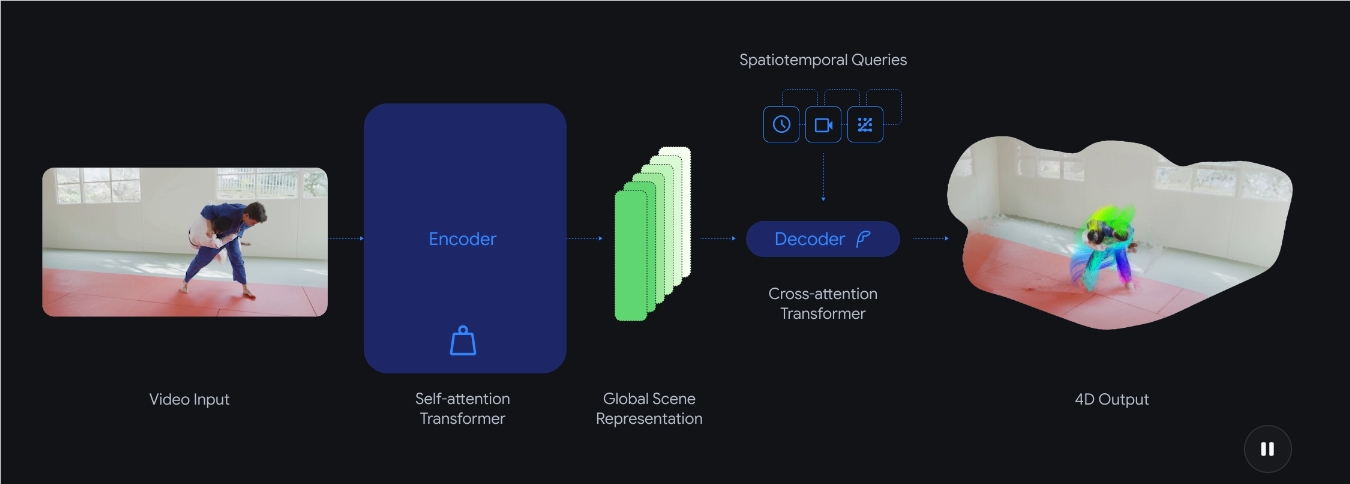
闪电般处理速度开启新可能
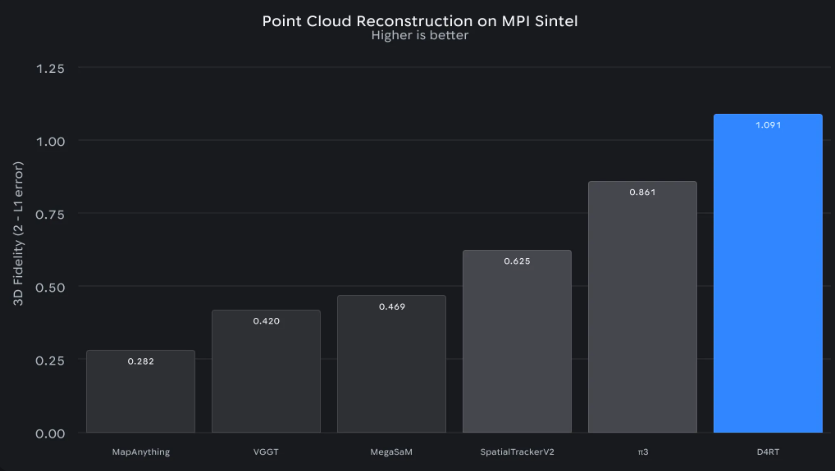
性能数据令人惊叹:基准测试中,D4RT处理视觉数据的速度比现有先进系统快18到300倍。过去需要超级计算机十分钟的分析任务,现在消费级硬件几秒即可完成。
"这不仅仅是渐进式改进",机器人工程师Mark Chen指出,"速度突破意味着AI终于能跟上现实世界的运动节奏——这对自动驾驶汽车或手术机器人等应用至关重要"。
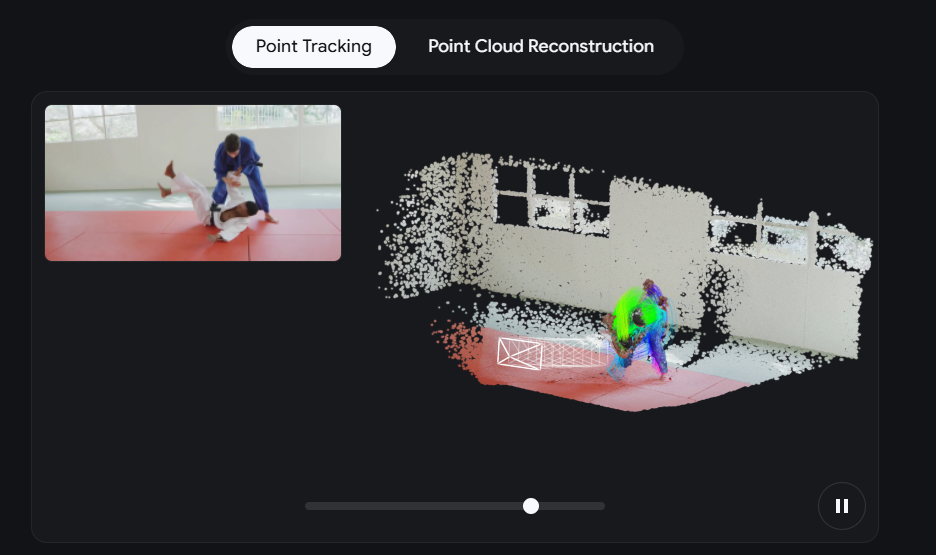
三项突破性能力
该系统展现出远超单纯速度的卓越能力:
- 持续目标追踪:即使物体离开镜头视野或被暂时遮挡,D4RT仍能保持对其位置和轨迹的感知
- 即时3D建模:无需耗时的迭代处理即可生成完整三维场景重建
- 摄像机运动检测:通过分析多视角数据精确判断拍摄设备自身的空间移动轨迹
这些能力预示着跨行业的变革性应用——从在拥挤车间自如穿行的制造机器人,到将数字内容无缝融入物理环境的AR眼镜。
展望未来:机器感知的新纪元
The implications extend far beyond technical specifications. As AI begins perceiving our world dimensionally rather than as flat snapshots, we're witnessing a fundamental shift in how machines understand reality itself. It's not just about seeing better—it's about comprehending the fluid nature of space and time that humans take for granted.
The research team has published detailed technical specifications and early implementation case studies on their blog. Industry analysts predict we'll see practical applications emerging within two years across robotics, autonomous systems, and immersive technologies.