谷歌AI推出Stax,支持自定义大语言模型评估
谷歌AI推出Stax支持自定义LLM评估
谷歌AI发布了实验性评估工具Stax,旨在帮助开发者更精准地评估大语言模型(LLMs)。与传统软件测试不同,LLMs是概率性系统,对相同提示可能产生不同响应,这使得一致性评估变得复杂。Stax为此提供了结构化解决方案框架。
突破传统基准测试的局限
虽然排行榜和通用基准能追踪模型的高阶进展,但往往无法反映领域特定需求。例如在开放域推理表现优异的模型,可能在法律文本分析或合规摘要任务中表现欠佳。Stax允许开发者根据实际用例定义自定义评估流程。
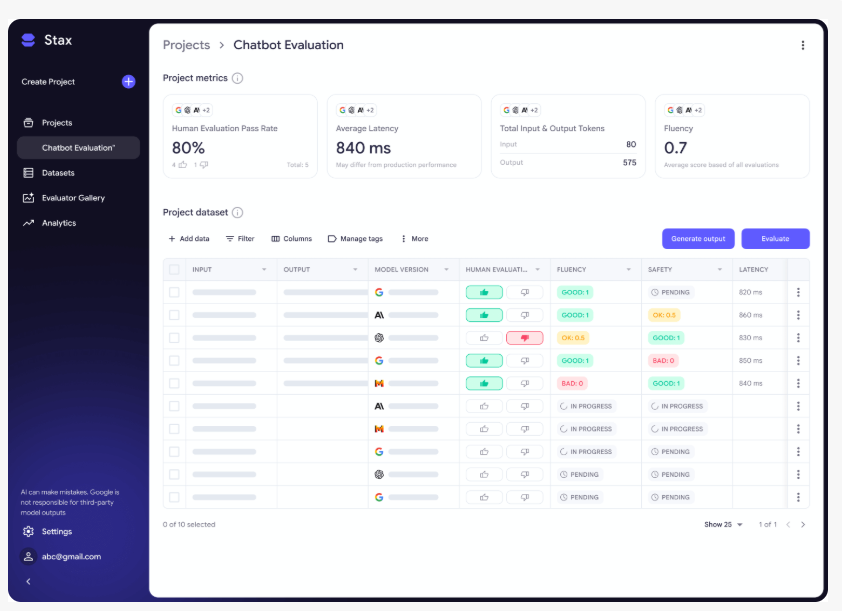
Stax核心功能
快速对比
通过快速对比功能,开发者可并行测试不同模型对多组提示的响应。该功能通过揭示提示设计或模型选择对输出的影响,减少试错时间。
项目与数据集
针对大规模测试场景,开发者可创建结构化测试集并应用统一的评估标准。这既保证了结果可复现性,也支持真实环境下的条件评估。
自动评估器
Stax的核心组件是自动评估器,支持开发者使用预制模块或构建定制评估器。内置评估器涵盖:
- 流畅度:语法正确性与可读性
- 事实性:与参考材料的一致性
- 安全性:避免有害或不恰当内容
深度洞察分析面板
Stax的分析面板通过可视化呈现以下内容简化结果解读:
- 性能趋势曲线
- 不同评估维度的输出对比
- 同数据集下的模型表现差异
这种从临时测试到结构化评估的转变,帮助团队更深入理解生产环境中的模型行为特征。
关键要点
- 🚀 Stax是谷歌AI推出的LLM自定义评估实验工具
- 🔍 快速对比和项目与数据集功能显著提升测试效率
- 📊 同时支持定制化与预制评估器满足领域特定需求





