费飞·李的团队开发先进的多模态模型
引言
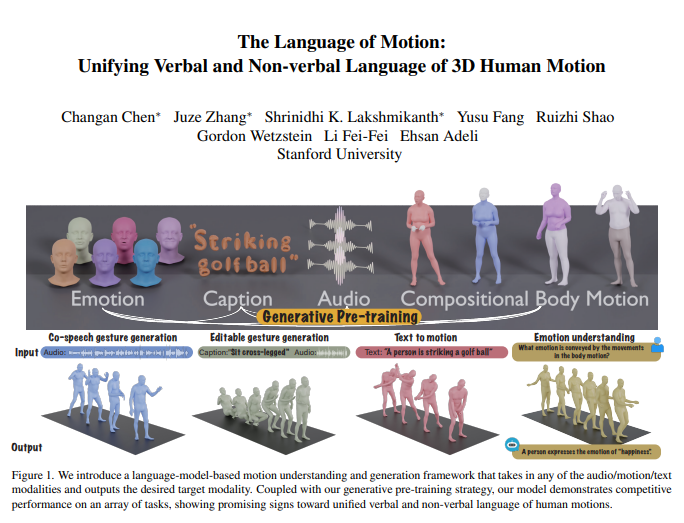
斯坦福大学的研究人员,费飞·李领导的团队开发了一种新的多模态模型,增强了对人类动作和语言的理解。这个创新模型不仅能够解释命令,还能解读隐含的情感,显著改善人机交互。
模型概述
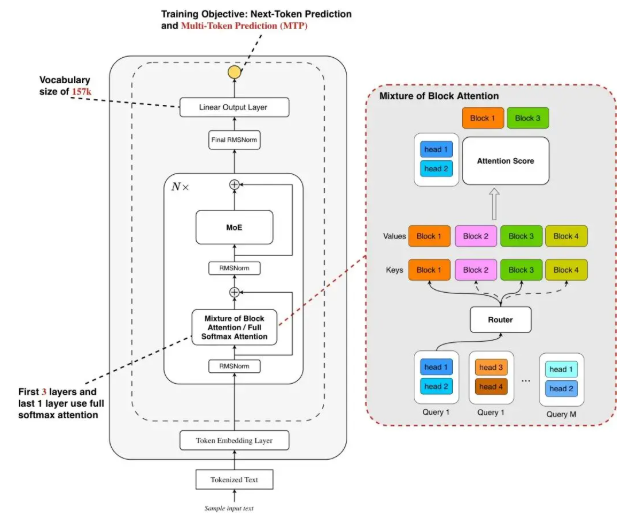
该模型的核心围绕其多模态语言模型框架,处理包括音频、动作和文本在内的多种输入。通过结合这些模态,模型生成反映口头和非口头交流的响应。这种整合允许机器理解人类指令,同时解读通过动作传达的情感线索,促进人类与技术之间更直观的互动。
突破性特征
研究表明,该模型在协作语音-手势生成方面表现出色,超越了现有技术,同时明显减少了所需的训练数据。这一突破为可编辑手势生成和情感预测等应用开辟了新可能性。
人类沟通本质上是多模态的,包含诸如语言和面部表情、身体语言等非语言线索。该模型解码这些多样的交流形式的能力,对于开发能够在各种环境中进行自然互动的虚拟角色至关重要,包括游戏、电影和虚拟现实。
集成语言模型的优势
研究人员确定了使用语言模型统一口头和非口头交流的三个主要原因:
- 自然连接:语言模型本质上链接不同的模态。
- 语义推理:应对幽默等任务需要强大的语义理解,而语言模型提供了这种能力。
- 广泛的预训练:这些模型通过广泛的训练获取强大的语义知识。 ### 训练方法
为了实现该模型,团队将人体分为不同部分——面部、手部、上肢和下肢——并为每个部分标记动作。他们为文本和语音创建了一种分词器,允许任何输入模态被表示为语言模型的标记。训练过程分为两个阶段:
- 预训练:将各种模态与相应的身体动作和音频/文本输入对齐。
- 下游任务:将任务转换为模型遵循的指令。 ### 性能和验证
该模型在BEATv2基准中协作语音-手势生成方面显示出卓越的结果,远远超出现有模型的性能。其预训练策略在数据有限的场景中特别有效,展示了强大的泛化能力。在进行语音-动作和文本-动作任务的后期训练后,模型能够跟随音频和文本提示,同时引入从动作数据中进行情感预测的功能。
技术框架
该模型采用特定模态的分词器来处理各种输入,训练一个联合身体运动的VQ-VAE,将动作转换为离散标记。这种方法将音频和文本的词汇合并为一个统一的多模态词汇。在训练期间,不同模态的混合标记作为输入,输出通过编码-解码语言模型生成。
在预训练阶段,模型学习执行跨模态转换任务,例如将上半身动作转换为相应的下半身动作,并将音频转换为文本。它还学习通过随机掩盖某些帧来捕捉动作的时间演变。
关键创新
在后期训练阶段,模型使用成对数据进行微调,以完成协作语音-手势生成和文本转动作生成等特定任务。为了促进自然指令的遵循,研究人员建立了一种多任务的指令遵循模板。这使得模型能够将音频转动作、文本转动作和情感转动作等任务解释为清晰的指令。此外,模型可以根据文本和音频提示生成协调的全身动作。
情感预测能力
该模型的一个显著进步是其从动作中预测情感的能力,这是在心理健康和精神病学应用中重要的特性。与其他模型相比,该系统在解读通过身体语言表达的情感方面显示出增强的准确性。
结论
这项研究强调了在人体动作中统一口头和非口头语言的重要性,指出语言模型是实现这一目标的强有力框架。这样的进展对于开发人机交互的实际应用至关重要,强调了与机器进行更自然沟通的潜力。
有关更多详细信息,请访问研究论文这里。
关键要点
- 费飞·李的团队开发了一种整合动作和语言的多模态模型。
- 该模型通过解读动作中的命令和情感来增强人机交互。
- 它在协作语音-手势生成方面显著超越了现有模型,并且需要更少的训练数据。
- 新功能包括可编辑手势生成和从动作中预测情感。
- 该模型的进展对于多个领域的应用至关重要,包括游戏和心理健康。