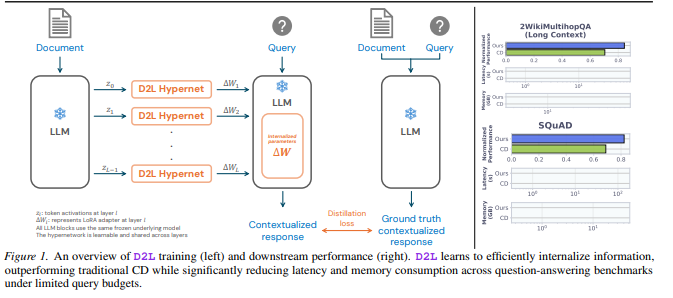
DeepSeek V4 发布多模态AI能力
DeepSeek准备通过V4发布实现AI重大飞跃
随着DeepSeek宣布其V4多模态模型将于下周发布,人工智能领域即将迎来变革。这不仅仅是一次渐进式更新——它代表了能力的显著扩展,可能重新定义我们与AI的互动方式。
AI生成领域的新突破
与之前专注于文本的模型不同,V4引入了原生支持生成图像和视频以及文本的功能。想象一下描述一个场景并看着AI将其视觉化呈现——这就是这项新技术的承诺。早期迹象表明,广告、教育和媒体制作领域的创意专业人士将从这些进步中受益最多。
"我们不仅仅是在改进现有功能,"公司发言人解释道,"V4为跨多种媒体格式的人机协作开启了全新的可能性."
技术透明度至关重要
此次发布将伴随详细的文档:
- 发布时立即提供技术概述
- 30天内提供全面的工程报告
- 持续的开发者资源
这种对透明度的承诺反映了DeepSeek在科技社区内建立信任的同时教育用户负责任地实施AI的关注点。
硬件合作伙伴推动本地创新
在幕后,DeepSeek一直与国内科技领导者密切合作:
- 华为:为昇腾处理器优化
- 寒武纪:增强与本地AI芯片的兼容性
对国内硬件的战略重视可能会显著推动中国半导体行业的发展,同时减少对外国技术的依赖。
这对创作者意味着什么
实际应用令人惊叹:
- 营销人员可以比以往更快地原型化活动
- 教育工作者可以即时开发定制的视觉辅助工具
- 内容创作者可以无缝地在不同媒体格式之间进行实验
仅潜在的时间节省就使得这次发布对任何从事数字内容工作的人都值得关注。
关键点:
- 多模态掌握:单一平台处理文本、图像和视频生成
- 本地化重点:专为中国硬件生态系统设计
- 创意革命:民主化复杂的内容生产工具