DeepSeek-OCR 2 正式发布,实现类人文档阅读能力
DeepSeek 为文档 AI 树立新标杆
在文档处理技术的重大飞跃中,DeepSeek 发布了 OCR 2,这一尖端系统终于弥合了机器与人类理解复杂文档之间的鸿沟。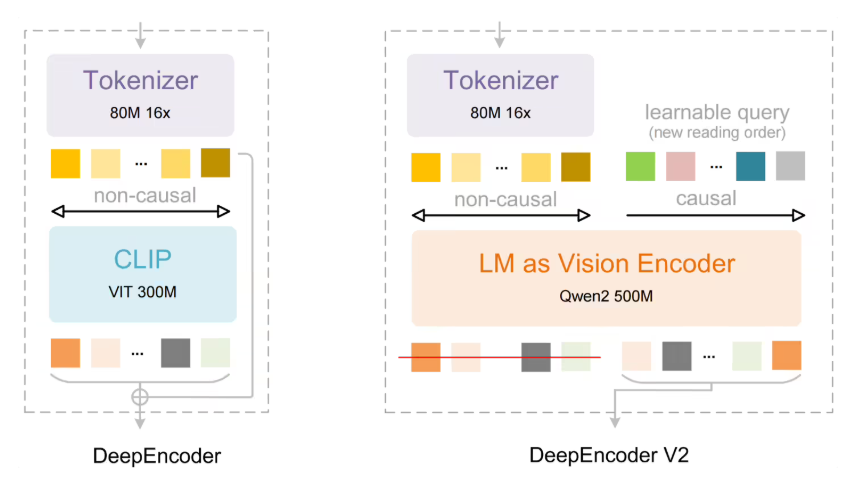
像人类一样阅读
真正的变革在于 DeepSeek 创新的"视觉因果流"方法。传统 OCR 系统像扫描仪一样机械地左右、上下处理文档。但人类的阅读方式并非如此——我们会根据意义和上下文在标题、说明文字和关键数据点之间跳转视线。
"这是首个真正模拟人类阅读模式的系统,"DeepSeek团队解释道。他们的 DeepEncoder V2 技术首先分析文档语义,然后智能确定最合理的处理顺序后再提取文本。
可量化的改进
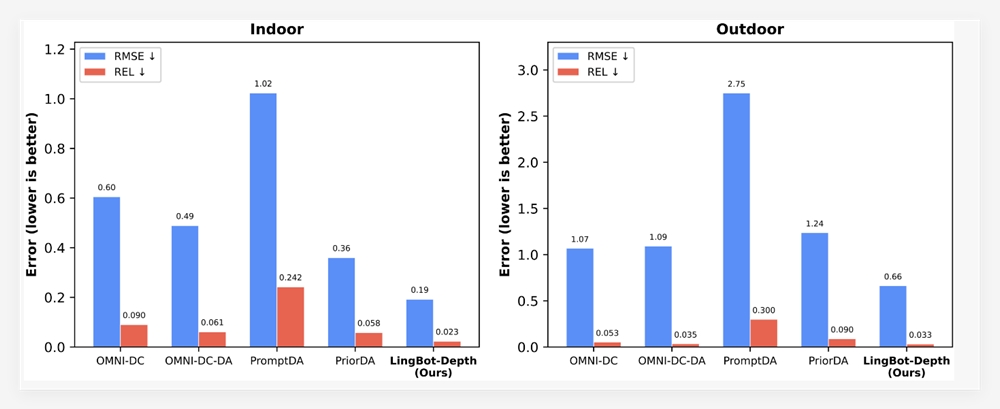
独立基准测试结果令人印象深刻:
- 91.09% 在 OmniDocBench v1.5 上的整体准确率(较前代提升 3.73%)
- 42%减少的阅读顺序错误
- 更低的重复率在实际 PDF 批量处理中表现优异
成功秘诀?将新型视觉编码器与高效的专家混合(MoE)语言解码模型巧妙结合。这种架构在不增加计算需求的情况下提供更好结果——这在 AI 发展中实属难得的双赢方案。
日常应用的重要意义
对于被文书淹没的企业或需要分析海量文档的研究人员而言,这些改进意味着:
- 数字化合同或表格的错误更少
- 含公式的复杂科学论文转换更准确
- PDF转换为可编辑格式时能更好保留文档结构
该系统尤其擅长处理:
- 财务报表和报告
- 含数学符号的学术论文
- 杂志报纸常见的多栏布局
关键亮点:
- 智能扫描:基于上下文而非机械地阅读文档
- 验证性能:基准测试中准确率提升3.7%
- 高效设计:无需更强算力即可获得更好结果
- 实战就绪:轻松应对杂乱PDF和复杂版面