苹果AI论文遭遇波折:基准测试错误引发深夜调试狂潮
苹果视觉推理论文因基准测试错误曝光需紧急修正
本周AI研究界因一篇提交至ICLR 2025的苹果论文曝出缺陷而争议不断。这项大胆宣称小型模型能超越GPT-5视觉推理能力的研究,其方法论正面临严重质疑。
震动团队的发现
杰初之星研究员杨磊在尝试复现研究结果时偶然发现了令人不安的矛盾之处。“起初我以为肯定是自己操作有误,”杨磊坦言,“后来才发现官方代码完全遗漏了关键图像输入。”
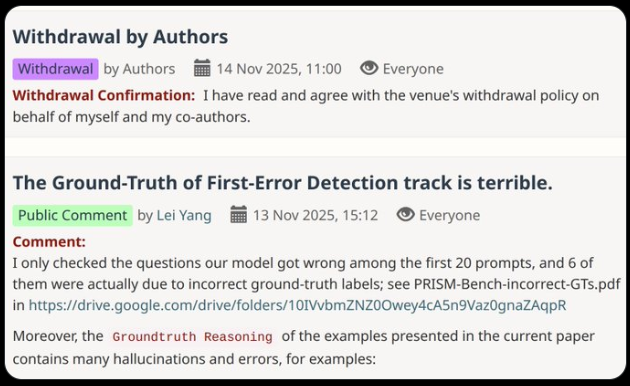
问题不止于此。当杨磊检查20个测试问题的样本时,发现有6个包含错误的真实标签——这一错误率表明近三分之一的基准数据可能存在问题。
迅速响应但余波未平
杨磊在GitHub上提交的问题起初鲜少受到关注,随后被突然关闭。他并未气馁,发表了一篇详细批评文章,很快在学术圈疯传。24小时内,苹果研究团队承认“数据生成过程中存在缺陷”,并紧急发布了修正后的基准测试。
该事件凸显了AI研究方法论中的成长阵痛:
- 缺乏适当验证检查的自动化数据集生成
- 证明超越大型模型突破的压力
- 当错误溜过时的人力成本——无数时间被浪费在复现有缺陷的工作上
“在你为复现熬夜前,”杨磊建议同行研究者,“先快速做个诊断检查。”
这一插曲成为了一个警示故事:即使在激烈竞争推动人工智能边界扩展的过程中,也要保持严谨标准。
关键点:
- 苹果论文宣称小型模型在视觉推理任务上击败GPT-5
- 独立研究员发现缺失的代码组件和影响约30%基准数据的标签错误
- 研究发现促使原作者紧急修正
- 事件引发关于AI研究方法论质量控制的讨论