阿里巴巴发布增强版Qwen-VL模型,数学与视频能力显著提升
阿里巴巴Qwen团队推出新型30B参数多模态AI模型
阿里巴巴集团Qwen(通义千问)研究部门发布了两款前沿小型多模态人工智能模型,旨在挑战行业领先基准。Qwen3-VL-30B-A3B-Instruct和Qwen3-VL-30B-A3B-Thinking模型均采用30亿活跃参数,同时提供媲美更大架构的性能表现。

技术能力与竞争定位
根据开发团队分享的内部基准测试,这些模型展现出:
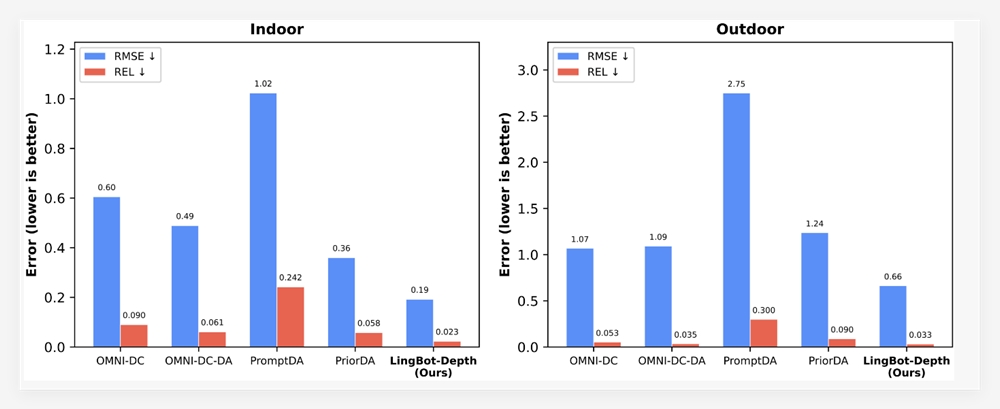
- 数学推理能力较前代Qwen提升28%
- 实际测试场景中视频帧处理速度加快19%
- 光学字符识别(OCR)准确率超越Claude4Sonnet
这些模型专门针对OpenAI的GPT-5-Mini和Anthropic的Claude4Sonnet架构实现竞争对标。早期测试显示其在以下方面具有突出优势:
- 复杂方程求解
- 跨模态数据解读(图像到文本)
- 长上下文视频分析
- 自主智能体协调任务
部署选项与可访问性
本次发布包含多种部署格式:
| 版本 | 精度 | 使用场景 |
|---|
开发者可通过以下渠道获取模型:
- HuggingFace Model Hub
- 阿里ModelScope平台
- 通过阿里云服务直接调用API
团队还部署了基于网页的聊天界面,展示模型的对话能力。
战略意义
此次发布体现了阿里巴巴对高效、小规模AI架构的持续投入,这些架构仍保持高性能标准。FP8优化特别满足了企业对高性价比推理解决方案日益增长的需求。
Qwen团队强调其通过无需专用硬件集群即可部署的可访问模型规模,致力于"实现高性能AI民主化"。
关键要点:
- 双模型发布分别针对指令跟随和推理任务
- STEM相关基准测试显示15-28%的性能提升
- 完全兼容现有阿里云AI基础设施 完整模型权重和文档现已根据商业许可条款提供。