Xiaohongshu's Open-Source Multimodal Model Rivals Top AI
Xiaohongshu's Open-Source Multimodal Model Challenges Industry Leaders
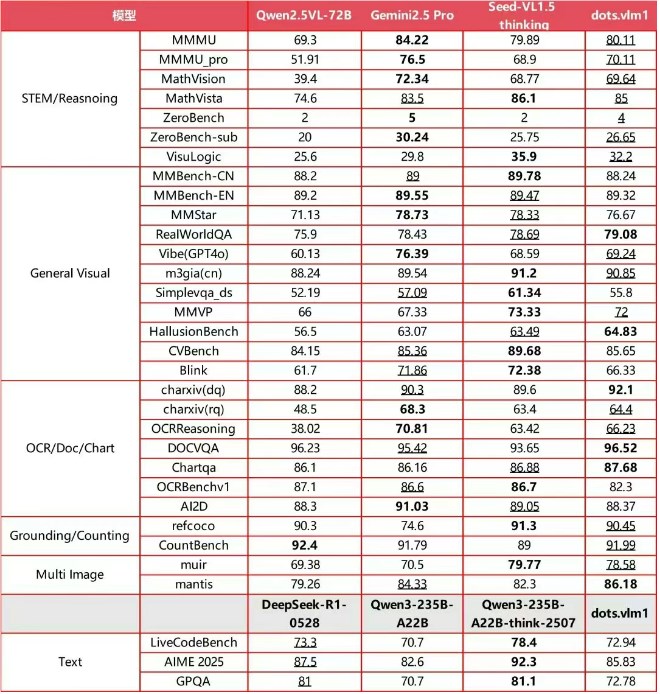
Chinese social media platform Xiaohongshu has entered the AI arms race with the release of dots.vlm1, its first self-developed multimodal large model. The open-source system combines a 1.2B parameter NaViT visual encoder with the DeepSeek V3 large language model, achieving performance comparable to proprietary models like Google's Gemini2.5Pro.

Native Architecture Breaks New Ground
The model's standout feature is its completely self-developed architecture, trained from scratch rather than fine-tuned from existing models. The NaViT encoder supports dynamic resolution processing, allowing superior handling of real-world image variability. Through dual supervision combining pure visual and text-visual training, the system demonstrates exceptional capability with non-standard content including:
- Tables and charts
- Mathematical formulas
- Document structures
"We rebuilt our entire training pipeline," explained the Hi Lab team. "From data collection using our dots.ocr tool for PDF processing to manual rewriting of web-sourced text, every component was optimized for cross-modal understanding."
Benchmark Performance Analysis
In rigorous testing across international evaluation sets, dots.vlm1 shows remarkable results:
| Benchmark | Performance Level |
|---|
The model particularly shines in complex analytical tasks, solving Olympiad-level math problems and demonstrating strong STEM reasoning capabilities. While trailing slightly in advanced textual reasoning, its mathematical and coding performance equals leading LLMs.
Future Development Roadmap
The Hi Lab team outlined three key focus areas for future development:
- Data expansion: Scaling cross-modal training datasets
- Algorithm enhancement: Implementing reinforcement learning techniques
- Reasoning improvement: Boosting generalization capabilities
By open-sourcing dots.vlm1, Xiaohongshu aims to stimulate innovation in the multimodal AI space while establishing itself as a serious player in foundational model development.
Key Points:
- First complete open-source multimodal model from Xiaohongshu
- Native NaViT encoder handles dynamic resolution natively
- Matches proprietary models in 6/8 benchmark categories
- Exceptional performance on STEM and analytical tasks
- Planned enhancements through RL and data scaling