Tsinghua's New Tool Simplifies Audio AI Evaluation
Tsinghua Researchers Democratize Audio AI Evaluation
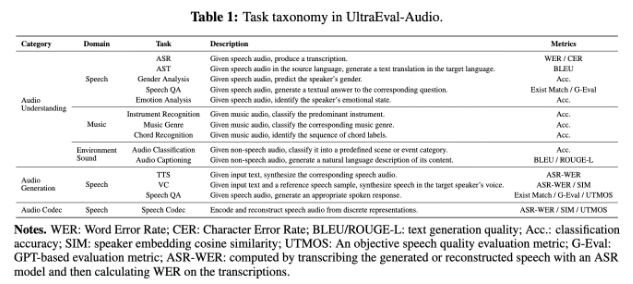
In a significant move for the audio AI community, Tsinghua University's NLP Lab has partnered with OpenBMB and Miga Intelligence to release UltraEval-Audio - an open-source framework that's changing how researchers evaluate audio models. This isn't just another technical tool; it's a potential game-changer for developers working on everything from voice assistants to podcast transcription services.
The newly released v1.1.0 version packs several practical upgrades:
- One-click model reproduction lets researchers quickly replicate popular audio models
- Expanded support covers specialized areas like Text-to-Speech (TTS) and Automatic Speech Recognition (ASR)
- New isolated inference operation makes evaluations more controllable and portable
"What excites us most is how this lowers barriers," explains Dr. Li Wei from Tsinghua's NLP Lab. "Previously, evaluating different audio models required setting up multiple environments - now researchers can focus on innovation rather than infrastructure."
The framework has already proven its worth, becoming the evaluation standard for influential models like MiniCPM-o2.6 and VoxCPM. Its open-source nature means any developer can access these professional-grade tools through GitHub.
Why This Matters Beyond Academia
While technical details might seem niche, the implications reach far beyond university labs:
- Faster innovation cycles: Reduced evaluation time means quicker iterations on voice technologies we use daily
- Standardized benchmarks: Creates common ground for comparing different approaches
- Resource efficiency: Smaller teams can achieve what previously required major infrastructure
The GitHub repository (https://github.com/OpenBMB/UltraEval-Audio) shows growing community engagement, with developers worldwide contributing to its evolution.
Key Points:
- 🎯 Evaluation simplified: UltraEval-Audio provides standardized tools for assessing audio AI models
- ⚡ Practical upgrades: Version 1.1.0 adds one-click reproduction and broader model support
- 🌍 Open access: Available on GitHub for global research community
- 🚀 Real-world impact: Already adopted by leading audio AI projects