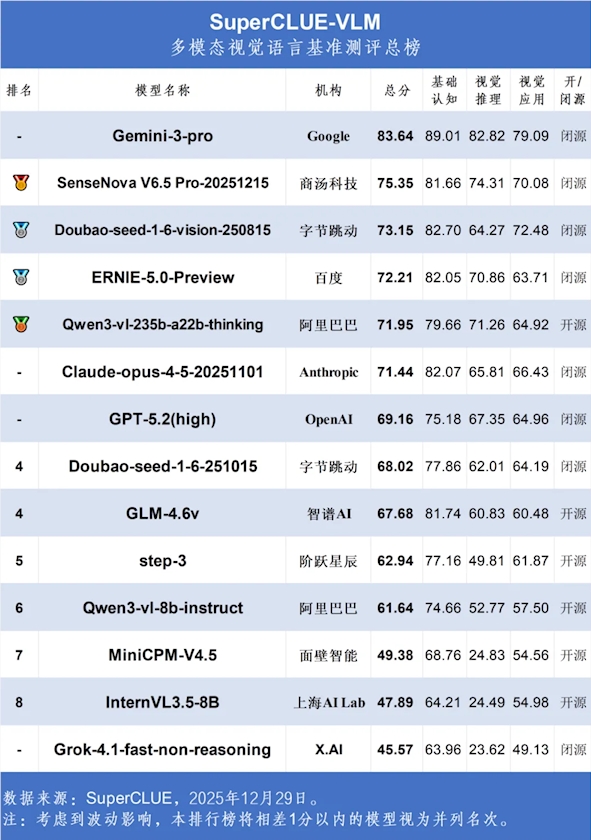
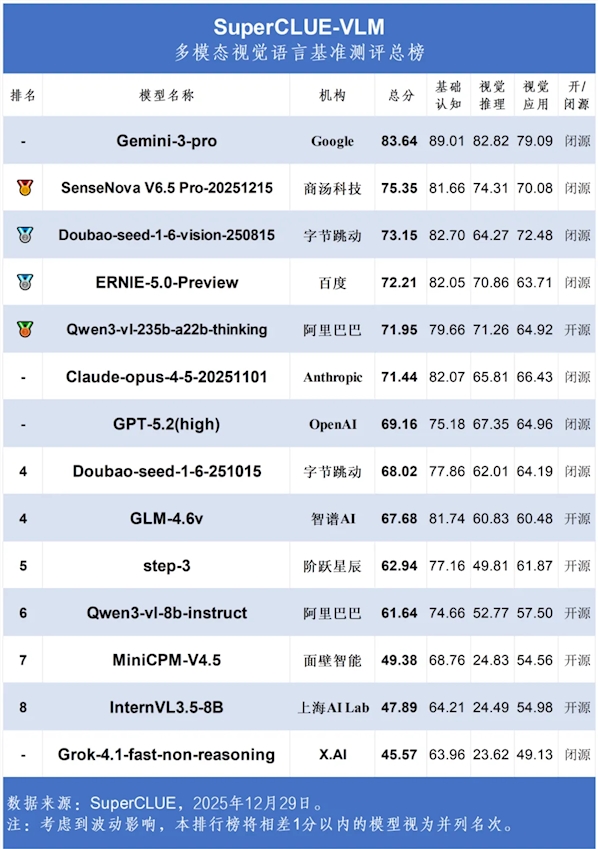
Shanghai AI Lab Launches First Video-to-Web Benchmark
Shanghai AI Lab Unveils Groundbreaking Video-to-Web Benchmark
The Shanghai Artificial Intelligence Laboratory has launched IWR-Bench, the world's first evaluation framework designed to assess how well large language models can transform video demonstrations into functional web code. This innovative benchmark addresses a critical gap in assessing multimodal AI systems' capabilities for dynamic web reconstruction.
Breaking New Ground in AI Evaluation
Unlike traditional image-to-code tasks, IWR-Bench presents models with videos capturing complete user interactions alongside all necessary static webpage resources. The system then evaluates how accurately models can recreate the observed dynamic behaviors across various complexity levels - from basic web browsing to sophisticated applications like the 2048 game and flight booking systems.
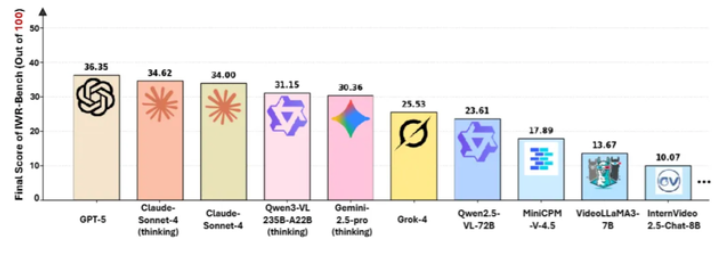
Surprising Performance Gaps Revealed
Initial testing of 28 leading AI models yielded sobering results:
- GPT-5 emerged as top performer with just 36.35/100 overall score
- Interaction Function Score (IFS): 24.39%
- Visual Fidelity Score (VFS): 64.25%
The significant disparity between visual restoration (64.25%) and functional accuracy (24.39%) highlights fundamental challenges in translating observed behaviors into working code logic.
Innovative Evaluation Methodology
The benchmark employs several novel assessment techniques:
- Proxy-based automated testing verifies interactive functionality
- Complete but anonymized static resources force visual matching rather than semantic shortcuts
- Temporal understanding tests track state changes across video frames
- Multi-dimensional scoring evaluates both appearance and functionality
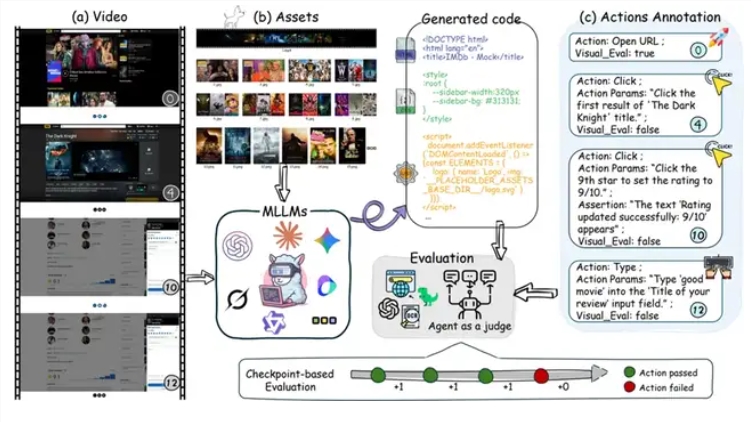
Technical Challenges Identified
The research uncovered four major hurdles for current AI systems:
- Temporal understanding: Extracting key events from continuous video frames
- Logical abstraction: Converting behaviors into programming concepts like event listeners
- Resource matching: Correctly associating anonymized files with visual elements
- Code generation: Producing structurally sound HTML/CSS/JavaScript
The findings suggest that even advanced multimodal models struggle with causal reasoning and state management required for dynamic web reconstruction.

Industry Implications
The benchmark's creators emphasize its dual significance:
- Research value: Provides new metrics for evaluating dynamic understanding capabilities
- Practical potential: Could eventually lower barriers to front-end development if technology matures However, researchers caution that high benchmark scores wouldn't immediately translate to production-ready tools, noting critical gaps in handling performance optimization, security, and edge cases.
Key Points:
- First specialized benchmark for video-to-webpage conversion unveiled
- GPT-5 leads but scores just 36.35/100 overall
- Models show strong visual restoration (64%) but weak interaction logic (24%)
- Reveals fundamental gaps in temporal reasoning and state management
- Could shape future "what you see is what you get" development tools