OmniGen2 - Multimodal AI Image Generator
Product Introduction
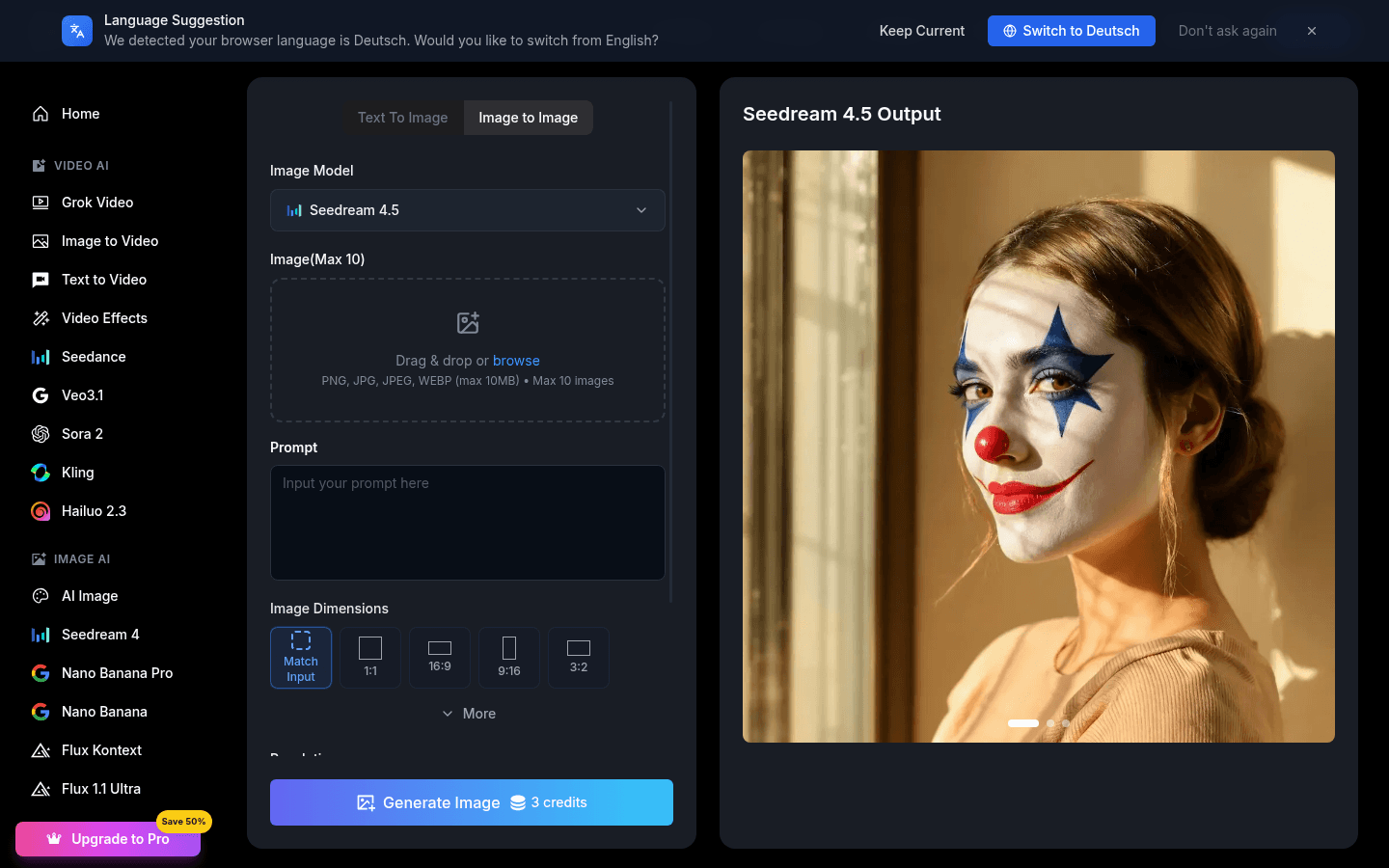
OmniGen2 is an efficient multimodal generative model that integrates visual language models with diffusion models. This powerful combination enables advanced visual understanding, high-quality image generation, and precise image editing capabilities. As an open-source solution, it provides researchers and developers with a robust foundation for exploring personalized and controllable AI generation.
Key Features
- Visual Understanding: Advanced image content analysis capabilities
- Text-to-Image Generation: Creates high-quality images from text prompts
- Instruction-Guided Editing: Executes complex image modifications with precision
- Contextual Generation: Processes multiple inputs to create novel visual outputs
- Multi-Format Support: Works with various input formats for flexible applications
- User-Friendly Interface: Includes online demo platform for easy experimentation
- Open-Source Availability: Complete codebase and datasets available for research
Product Data
- Target Users: Researchers, developers, and designers needing advanced image generation tools
- Use Cases:
- Generating images from text descriptions
- Modifying existing images based on instructions
- Creating visual content for marketing or educational materials
- Technical Requirements:
- Python 3.11 environment
- PyTorch 2.6.0 framework
- Additional dependencies specified in requirements.txt
Product Link
The official OmniGen2 repository can be found at: https://github.com/VectorSpaceLab/OmniGen2