DeepSeek V4 Launches with Two Versions: What Developers Need to Know
DeepSeek V4 Arrives with Dual Approach
The AI landscape just got more interesting. DeepSeek, a prominent player in China's artificial intelligence sector, has rolled out its V4 model with a clever twist: two specialized versions designed for different workloads. This isn't just another incremental update—it's a strategic move that could change how businesses implement AI solutions.
Flash vs Pro: Choosing Your AI Workhorse
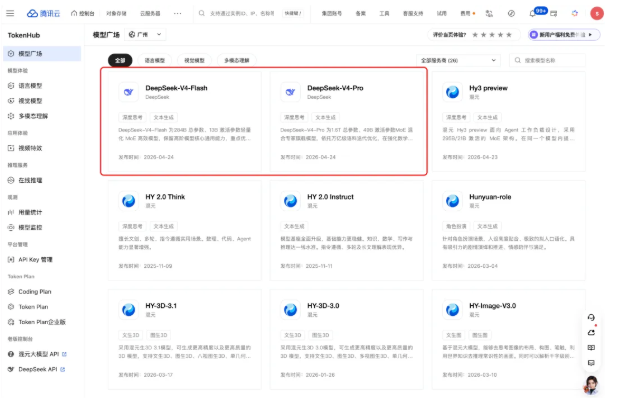
The new lineup replaces previous models with two clearly defined options:
- DeepSeek-V4-Flash: Built for speed and affordability, this version handles everyday conversations and basic text processing with impressive efficiency.
- DeepSeek-V4-Pro: When your project demands serious brainpower—complex analysis, deep reasoning tasks, or intensive computations—this is the heavyweight contender.
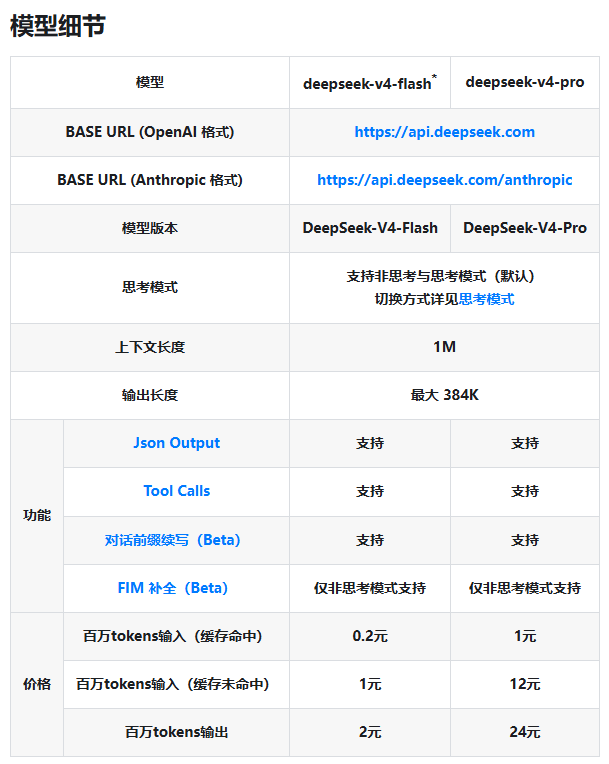
Both versions support advanced features like JSON output and Tool Calls, plus an expansive 1M context window that gives developers ample room for sophisticated applications.
Pricing That Rewards Smart Coding
The cost structure reveals DeepSeek's clever approach to resource management. By offering dramatically lower rates for cached requests (up to 80% cheaper), they're incentivizing developers to build smarter, more efficient applications. Here's what you'll pay per million tokens:
| Model | Input (Cache Hit) | Input (Cache Miss) | Output |
|---|
This tiered pricing could be a game-changer for startups and enterprises alike. The Flash version's entry point makes top-tier AI accessible, while the Pro option delivers serious power without completely breaking the bank.
Why This Release Matters
Beyond the specs sheet, this launch signals several important shifts:
- Specialization Wins: The days of one-size-fits-all AI models may be ending as providers tailor offerings to specific use cases.
- Cost Transparency: Clear pricing structures help businesses forecast expenses accurately—a welcome change from opaque cloud service bills.
- Performance Choices: Developers now have clear options to match their budget and performance needs.
The company has also announced that legacy model names will be phased out, so developers should start transitioning to the new V4 naming conventions now.
Key Points at a Glance
- Two distinct models: Flash for efficiency, Pro for power
- Significant cost savings through smart caching (up to 80%)
- Expanded context window (1M tokens) supports complex applications
- Legacy models (
deepseek-chat,deepseek-reasoner) being retired - Detailed migration guides available in official API documentation