Claude Opus 4.6 Takes the Crown in AI Benchmark Showdown
Claude Outshines GPT in Latest AI Benchmark Tests
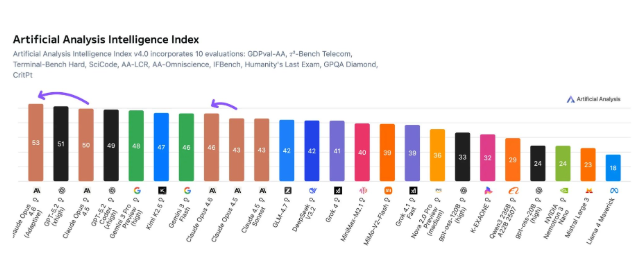
The artificial intelligence landscape has shifted once again as Anthropic's Claude Opus 4.6 claimed the top position in the prestigious Artificial Analysis Intelligence Index. This comprehensive evaluation puts AI models through their paces across ten rigorous tests, from programming challenges to physics problem-solving.
Efficiency Wins Despite Higher Costs
What makes Opus 4.6's performance particularly impressive? The model achieved its benchmark-topping results while demonstrating remarkable efficiency. During testing, it processed about 58 million output tokens - a significant improvement over GPT-5.2's 130 million token consumption. This efficiency edge comes despite Opus 4.6's slightly higher operational cost of $2,486 compared to GPT-5.2's $2,304.
"These numbers tell an interesting story," notes AI analyst Mark Chen. "While both models represent cutting-edge technology, Claude appears to be getting more bang for its buck when it comes to computational resources."
Where Claude Excels
The benchmark results reveal Opus 4.6's particular strengths:
- Agent task execution: Outperformed all competitors in complex, multi-step operations
- Terminal programming: Demonstrated superior coding capabilities
- Physics research: Showed advanced reasoning skills in scientific domains
Currently available on Claude.ai and through major cloud platforms like Google Vertex and AWS Bedrock, Opus 4.6 is proving its worth across various applications.
The Coming Challenge from OpenAI
Anthropic's celebration might be short-lived, however. Industry watchers are keeping a close eye on OpenAI's Codex 5.3, which is already undergoing preliminary testing. Early indications suggest this specialized programming tool could reclaim the coding crown for OpenAI when full benchmark results come in.
"The AI race is like watching Olympic sprinters constantly breaking each other's records," observes tech journalist Sarah Lim. "Just when one model pulls ahead, another comes along to push the boundaries further."
Key Points:
- Claude Opus 4.6 tops latest AI intelligence benchmarks
- 58M tokens processed vs GPT-5.2's 130M - demonstrating better efficiency
- $2,486 operational cost slightly higher than GPT-5.2 ($2,304)
- Excels in agent tasks, terminal programming, and physics research
- OpenAI's Codex 5.3 poised to challenge in coding-specific benchmarks

