Alibaba's New Algorithm Helps AI Think More Like Humans
Alibaba's Tongyi Lab Breaks New Ground in AI Reasoning
Researchers at Alibaba's Tongyi Lab have developed an innovative algorithm that could change how artificial intelligence handles complex reasoning tasks. The new approach, called FIPO (Future-KL Influenced Policy Optimization), addresses a fundamental challenge in large language models: identifying which pieces of information truly matter when working through multi-step problems.
The Reasoning Bottleneck
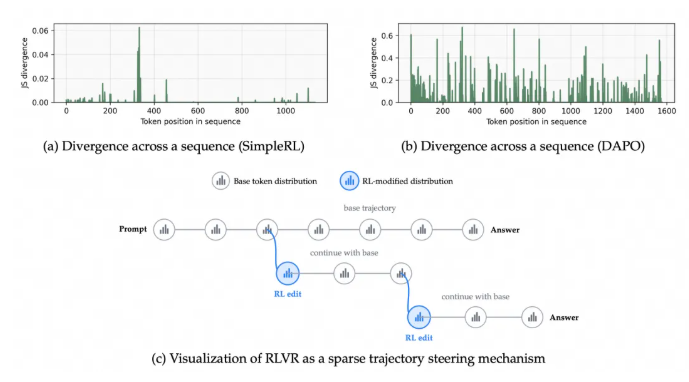
Current reinforcement learning methods often treat every piece of information equally when processing long chains of reasoning. "Imagine trying to solve a math problem where you can't tell which numbers actually affect the final answer," explains one researcher familiar with the project. "That's essentially the challenge these models face."
The FIPO algorithm introduces what the team calls a "Future-KL" mechanism. This clever approach specifically rewards tokens (the basic units of information in AI systems) that prove crucial for subsequent reasoning steps. It's like giving bonus points to the parts of a calculation that actually lead to the solution, rather than treating all steps as equally important.
Real-World Performance
In practical testing, FIPO has shown remarkable results. When applied to Alibaba's Qwen2.5-32B-Base model, it achieved average reasoning lengths exceeding 10,000 tokens - a significant leap forward. More importantly, it didn't just handle longer reasoning chains; it did so more accurately, particularly in complex mathematical problems.
The algorithm outperformed comparable models like o1-mini and DeepSeek-Zero-MATH in pure reinforcement learning setups. What makes these results particularly interesting is how they were achieved: by focusing on what researchers call "the directionality of optimization" - essentially teaching the AI to recognize which paths through a problem actually lead to solutions.
Why This Matters
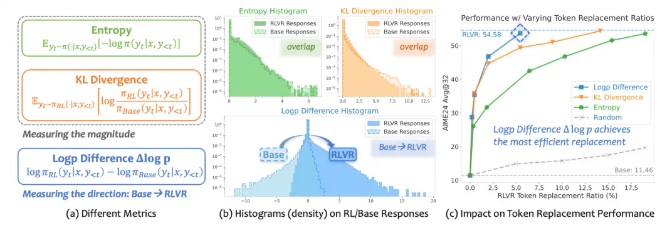
Most tokens in traditional AI training show little change before and after learning sessions - what researchers describe as "extremely sparse" impact. Common evaluation metrics often miss subtle but crucial changes in key tokens. FIPO introduces a new way to measure progress through something called Δlog p (difference in log probability of symbol pairs), giving developers better visibility into how their models are learning.
This breakthrough comes at a time when AI systems are increasingly being asked to handle complex, multi-step reasoning tasks - from scientific research to financial analysis. The ability to distinguish critical from incidental information could be key to developing more reliable and capable AI assistants.
Key Points:
- Smarter Focus: FIPO helps AI identify and prioritize the most important information in reasoning tasks
- Longer Reasoning: Enables handling of reasoning chains over 10,000 tokens long
- Better Accuracy: Shows significant improvements in complex mathematical problem-solving
- New Measurement: Introduces Δlog p as a more effective way to track learning progress