Zhipu Unveils GLM-4.5V: A Visual AI Model That Identifies Fast Food
Zhipu Launches Advanced Visual AI Model GLM-4.5V
August 12, 2025 — Zhipu Technology has officially released its latest visual understanding model, GLM-4.5V, marking a significant leap in AI-driven image analysis. Built on the foundation of its text model GLM-4.5-Air, this new iteration follows the technical framework of its predecessor, GLM-4.1V-Thinking, but with enhanced capabilities.
Technical Specifications
The model boasts 106 billion parameters, with 12 billion activated parameters, making it one of the most robust visual AI systems available. A standout feature is its "thinking mode" switch, which allows users to toggle advanced reasoning functions for more flexible task handling.
Performance Highlights
In demonstrations, GLM-4.5V showcased its ability to distinguish between McDonald's and KFC fried chicken wings by analyzing appearance, color, and texture. It also excelled in image-based location guessing challenges, outperforming 99% of human participants and securing a rank of 66th in competitive benchmarks.
Zhipu reported that the model achieved higher scores than comparable models in 42 benchmark tests, solidifying its position as a leader in visual AI.
Availability and Applications
The model is now accessible on platforms like Hugging Face, ModelScope, and GitHub, with a free-to-download FP8 quantized version. To enhance user experience, Zhipu introduced a desktop assistant application that supports real-time screenshot and screen recording for tasks such as code assistance and document interpretation.
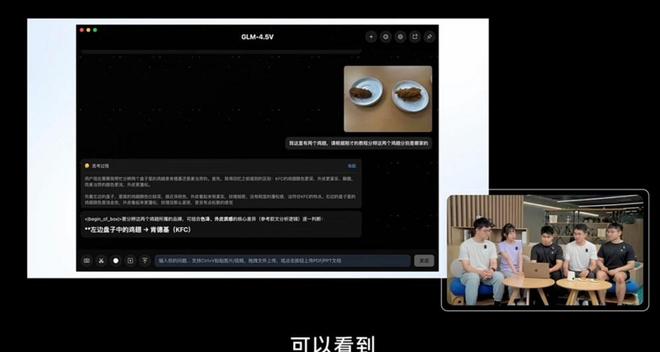
Practical Testing Insights
During trials, GLM-4.5V demonstrated strong location inference capabilities, though minor errors were noted. Its reasoning process was described as "rich" and detailed. The model also replicated web content with high accuracy using screenshots, highlighting its potential for automation.

Future Prospects
Beyond visual understanding, GLM-4.5V shows promise in Agent application scenarios. As the technology evolves, it could revolutionize industries requiring advanced image analysis.
Key Points:
- 106 billion parameters, with 12 billion activated.
- Features a "thinking mode" switch for customizable task handling.
- Outperforms humans in image-based challenges.
- Available on open-source platforms with a free FP8 quantized version.
- Potential applications in automation and Agent-based systems.