Zhipu Open-Sources GLM-4.5V, a Cutting-Edge Vision Reasoning Model
Zhipu Unveils GLM-4.5V: A New Benchmark in Vision Reasoning
Chinese AI company Zhipu has made a significant advancement in artificial intelligence by open-sourcing GLM-4.5V, currently the best-performing visual reasoning model at the 100B scale globally. This release marks another milestone in the company's pursuit of Artificial General Intelligence (AGI).
Technical Specifications and Availability
The model, featuring 106B total parameters with 12B activated parameters, is now accessible on both ModelScope and Hugging Face platforms. Built upon Zhipu's flagship text foundation model GLM-4.5-Air, GLM-4.5V continues the technical lineage of GLM-4.1V-Thinking while introducing substantial improvements.
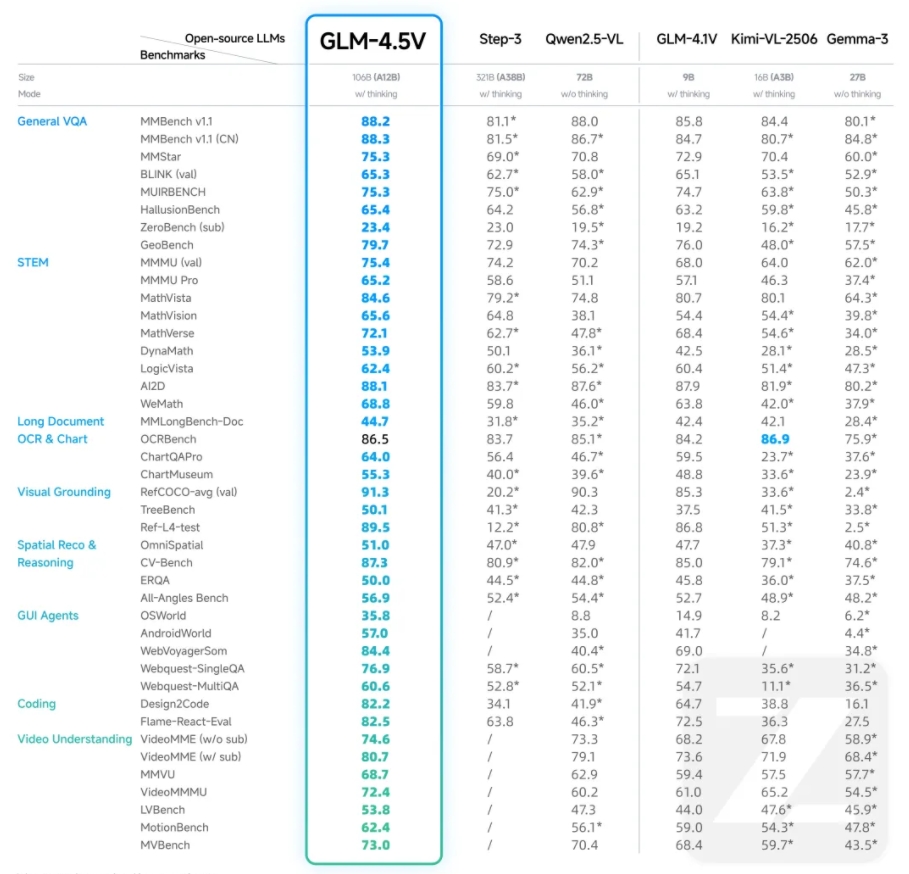
Performance and Capabilities
In rigorous testing across 41 public visual multimodal rankings, GLM-4.5V achieved state-of-the-art (SOTA) performance among open-source models of comparable scale. Its capabilities span:
- Image and video understanding
- Document interpretation
- GUI Agent functionality
- Complex chart analysis
The model introduces an innovative "thinking mode" switch, allowing users to toggle between rapid responses and deeper reasoning processes based on their needs.
Practical Applications and Developer Tools
To facilitate adoption, Zhipu has released:
- A desktop assistant application capable of real-time screenshot capture and screen recording
- Free API access through BigModel.cn with a 20 million Token resource package for new users
The API pricing is highly competitive at:
- Input: ¥2 per M tokens
- Output: ¥6 per M tokens With response speeds reaching 60-80 tokens/second.
Advanced Features and Technical Innovations
GLM-4.5V demonstrates exceptional performance in specialized areas including:
- Visual localization for precise object identification
- Front-end webpage replication capabilities
- Deep interpretation of complex documents (dozens of pages)
- Sophisticated GUI environment interactions The model architecture incorporates several technical breakthroughs:
- Visual encoder with MLP adapter and language decoder
- Support for 64K multimodal long context
- Enhanced video processing via 3D convolution
- Advanced image handling through bicubic interpolation mechanism
- Novel 3D Rotational Positional Encoding (3D-RoPE) for improved spatial reasoning
Key Points:
- GLM-4.5V sets new standards for open-source vision reasoning models at the 100B parameter scale.
- The model outperforms competitors across 41 multimodal benchmarks.
- Zhipu provides comprehensive developer resources including APIs and desktop applications.
- Innovative features like "thinking mode" enhance practical usability.
- The model's architecture incorporates multiple technical advancements for superior performance.