小米携Lobster AI助手低调亮相,主打隐私保护承诺
小米试水Lobster AI助手
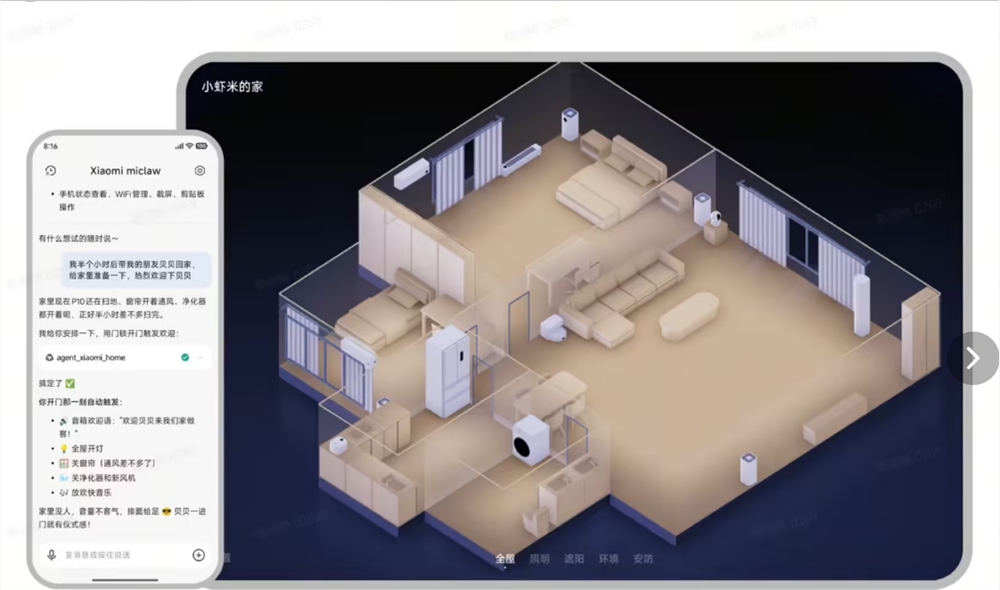
本周小米揭开了其实验性Lobster AI助手(代号'螃蟹')的神秘面纱,启动的独家封闭测试已在科技爱好者中引发热议。这不是传统的虚拟助手——小米将Lobster设想为系统级伙伴,可能从根本上改变我们与手机的交互方式。
与众不同的数字帮手
公司描述Lobster为移动优先的AI助手,设计用于在四个关键维度运行:
- 系统级访问以实现更深层功能
- 对用户情境的个性化理解
- 无缝的生态系统集成
- 持续的自我改进能力
目前仅通过邀请制向部分小米17系列用户开放,Lobster代表了小米对业界所称"原生AI助手"的雄心布局——这种智能代理直接内置于设备操作系统,而非作为附加功能后置。
以隐私为核心

此次发布正值消费者对科技公司处理个人数据的担忧日益增长之际。小米似乎敏锐意识到了这些忧虑,将隐私保护作为Lobster的核心卖点。
公司明确声明:不会使用任何用户数据训练其AI模型。相反,开发完全依赖合法获取的公共数据集和经过适当许可的材料。即使在实际使用中,您的指令也会在执行后消失,而非输入某个隐秘的训练数据库。
对于特别敏感的操作,小米采用其所谓的"端云隐私计算"技术——保持关键处理在本地进行,同时审慎使用云端资源。该方法建立了算法和物理屏障,防止个人数据流向不该去的地方。
尚待完善
请勿误解——Lobster仍处于实验阶段。早期测试者报告了预期的不足之处:
- 电池续航需要优化
- 复杂场景有时会令系统困惑
- 稳定性尚未达到成熟标准
限量发布让小米能在考虑广泛推广前完善这些方面。即便如此,在目前状态下Lobster已暗示了智能手机助手的未来方向。
该项目也作为小米MiMo大语言模型技术在传统聊天机器人应用之外的试验场。此处的成功可能验证移动AI的新方法——既重视能力又注重隐私保护。
随着制造商竞相重新定义智能手机通过人工智能能实现的功能,小米似乎决心不仅要参与其中,更要帮助制定竞争规则——尤其是在用户数据保护方面。
关键点:
- 限量测试版:目前仅限受邀的小米17用户
- 隐私重点:宣称零用户数据用于训练
- 本地处理:敏感操作保持在设备端进行
- 早期阶段:性能和稳定性有待改进