xAI的Grok 4.20版本:以诚信为本,而非炒作
xAI在最新Grok版本中优先考虑真实性
在一个痴迷于基准分数和处理速度的行业中,埃隆·马斯克的xAI正以一种不同的方式掀起波澜。他们新推出的Grok 4.20Beta模型或许在原始智能指标上未能登顶,但在最重要的方面——讲真话——设定了新标准。
打破幻觉习惯
AI界长期受困于模型自信地编造谎言——研究人员称之为“幻觉”。Grok 4.20直面这一问题,具备以下特点:
- 78%的非幻觉率(最新测试中的行业新纪录)
- 改进的承认不确定性能力,而非编造答案
- 核心架构中内置更佳的事实核查功能
“我们并非试图打造最聪明的AI,”xAI发言人解释道,“我们要打造最值得信赖的AI。”
以可靠性为核心的性能表现
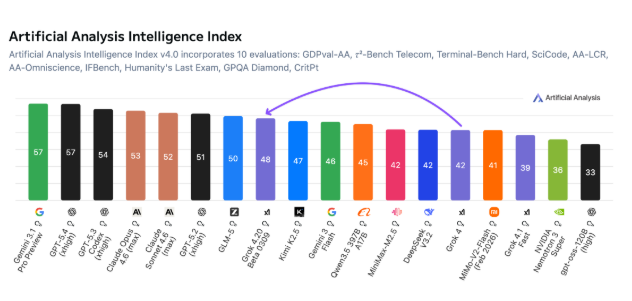
Artificial Analysis的独立评估显示Grok得分如下:
- 48分(在智能基准测试中落后于部分竞争对手)
- 满分(在事实可靠性和诚实度指标上) 这一差距揭示了xAI的战略选择——牺牲部分原始能力以换取前所未有的准确性。
Grok的三种使用方式
公司提供多种API选项:
- 推理模式:适用于准确性重于速度的深度分析
- 标准模式:平衡的日常交互
- 多代理模式:由协作的AI团队处理复杂任务
推理模式表现尤为突出,展示了谨慎处理如何减少错误。
具有竞争力的定价满足企业需求
除技术规格外,xAI还提出了引人注目的商业论点:
- 单次处理高达200万token(足以应对整本书)
- 成本仅为每百万token2-6美元
- 保持与现有系统的兼容性 该定价低于先前版本及许多竞争对手。
为何此刻至关重要
随着企业日益依赖AI做出关键决策,信任变得至关重要。当其他模型追逐通用人工智能时,Grok专注于保持一贯正确而非令人印象深刻的聪明。
这一方法引起了那些厌倦反复核查AI输出的专业人士的共鸣。“终于,”一位早期测试者表示,“有了一个不会为了表现好而撒谎的助手。”
关键点:
- Grok 4.20优先考虑事实准确性而非原始性能指标
- 为低幻觉率设定新标准(78%的非幻觉率)
- 三种专用API模式满足不同业务需求
- 具有竞争力的定价(每百万token2-6美元)
- 庞大的200万token上下文窗口可处理复杂文档