VLM2Vec-V2:多模态检索的统一框架
多模态学习的突破:VLM2Vec-V2桥接视觉数据类型
来自Salesforce Research、加州大学圣塔芭芭拉分校、滑铁卢大学和清华大学的合作研究团队发布了VLM2Vec-V2,这是一个革命性的多模态嵌入学习框架,旨在统一图像、视频和视觉文档的检索任务。
解决当前局限性
现有的多模态嵌入模型主要关注来自MSCOCO、Flickr和ImageNet等数据集的自然图像。这些模型在处理更广泛的视觉信息类型(包括文档、PDF、网站、视频和幻灯片)时表现不佳,导致在文章搜索和视频检索等实际应用中存在性能差距。
扩展能力
VLM2Vec-V2框架引入了多项关键进展:
- 扩展的MMEB数据集,包含五种新任务类型
- 支持视觉文档检索
- 增强的视频检索能力
- 时间定位功能
- 集成的视频分类和问答功能
技术创新
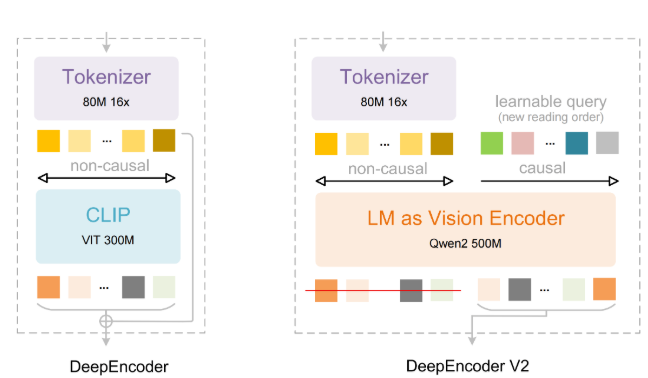
该模型基于Qwen2-VL架构,融合了以下技术:
- 简单的动态分辨率
- 多模态旋转位置嵌入(M-RoPE)
- 结合2D/3D卷积的统一框架
- 灵活的数据采样管道,用于稳定的对比学习
性能基准测试
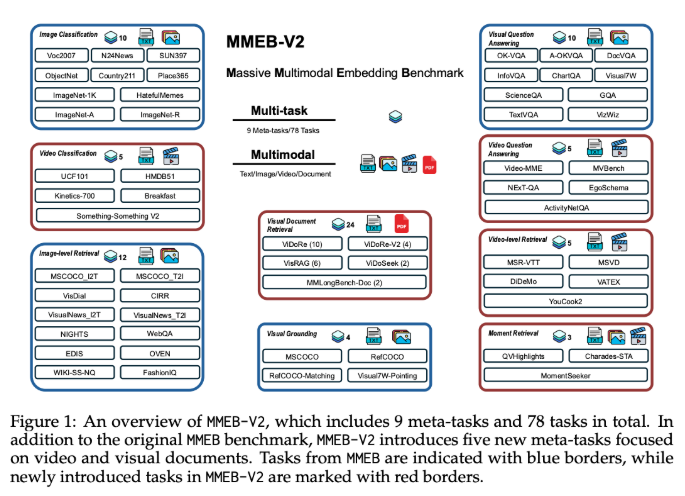
在涵盖78个数据集的全面测试中,VLM2Vec-V2取得了以下成果:
- 58.0的最高平均分
- 在图像和视频任务中均表现出色
- 在文档检索方面与ColPali等专用模型相比具有竞争力
该框架现已在GitHub和Hugging Face上发布。
关键点:
- 🚀 **统一框架适用于图像、视频和文档的检索任务
- 📊 扩展评估数据集包含多样化任务类型
- ⚡ 在全面测试中超越现有基准性能
- 🔍 开源可用性加速研究采用