vLLM-Omni突破多模态AI处理壁垒
vLLM-Omni开启多模态AI新时代
在一场令开发者兴奋的技术展示会上,vLLM团队揭晓了他们的最新创新成果:vLLM-Omni。这不仅仅是一次渐进式更新——而是对AI系统如何同时处理多种数据类型的彻底重构。
超越文本:面向全媒体的框架
虽然大多数语言模型仍仅限于文本领域,但现代应用需要远不止于此。想象一个不仅能阅读消息,还能理解分享的照片、分析语音笔记甚至生成视频回复的AI助手——这正是vLLM-Omni致力实现的未来。
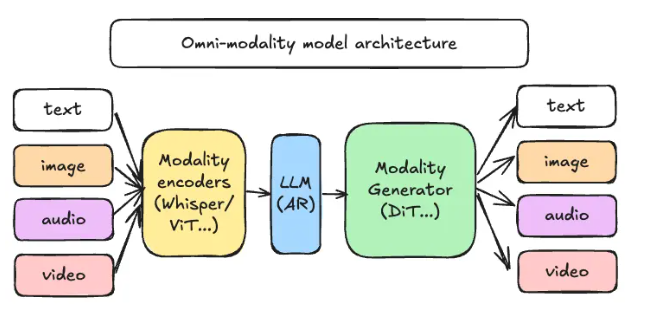
该框架的核心在于其解耦流水线架构,运作方式如同组织有序的工厂装配线:
- 模态编码器:将图像、音频片段或视频帧转换为机器可读向量
- 大语言模型核心:处理传统语言任务和对话的大脑
- 模态生成器:根据简单文本提示生成丰富媒体输出
为开发者带来的实际优势
这对工程团队意味着什么?灵活性与高效性。资源可以针对每个处理阶段独立扩展——不再因组件闲置而浪费GPU算力。在我们的演示中,系统动态地在分析图像和生成伴随叙述之间调配计算资源。
GitHub仓库已显示出活跃的开发迹象,早期采用者正在尝试从自动化视频编辑到交互式教育工具等各种创意应用。
"我们看到对跨多媒介类型理解上下文模型的需求正在激增,"首席工程师Maya Chen解释道,"vLLM-Omni为开发者提供了满足这一需求的工具包,无需每次都从头造轮子。"
关键要点:
- 🚀 真正的多模态处理无缝应对文本、图像、音频和视频
- ⚙️ 模块化架构实现精准资源分配
- 🌍 开源可用性促进全球协作
- 🏗️ 可扩展设计适应多样化应用需求




