腾讯新AI模型赋予机器人类人空间感知能力
腾讯突破性进展让机器人更接近人类理解能力
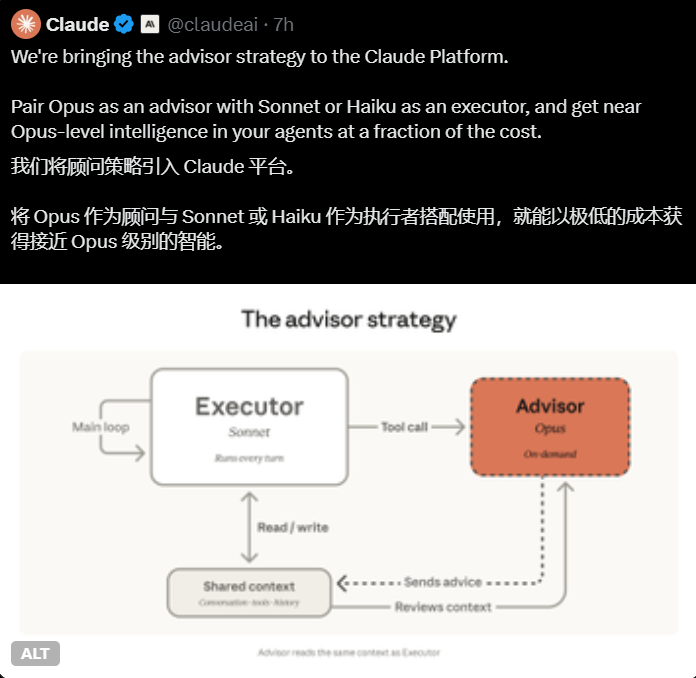
在机器人技术的重大飞跃中,腾讯研究团队开发出一个AI模型,终于让机器获得了我们习以为常的能力——对物理空间的直觉理解。他们的新HY-Embodied-0.5系统不仅仅是一次算法更新,更是对人工智能如何与三维世界互动的基础性重新思考。
为何重要
当今大多数AI视觉系统就像游客阅读外国城市地图——他们能识别地标但难以理解深度和空间关系。腾讯的解决方案更像本地居民,本能地知道物体在空间中的关系以及如何操控它们。这种能力差距长期阻碍了AI从屏幕走向实际机器人应用。
"典型的视觉语言模型擅长识别照片中的物体,"腾讯研究员解释道,"但让它们引导机器人手臂拾取并整理这些物体时,它们就会力不从心。我们的新架构改变了这一局面。"
技术原理
团队不仅调整了现有模型——他们还从零开始构建了两个专用版本:
- MoT-2B:精简高效模型(总共40亿参数),专为边缘设备实时响应设计
- MoE-32B:强大变体(4070亿参数),为复杂任务提供卓越推理能力
关键创新包括新颖的混合Transformer架构,可防止多模态训练中常见的"灾难性遗忘"问题,以及先进的视觉编码技术,保持对物理交互至关重要的精细细节。
卓越性能
独立测试显示出显著成果:
- 在22项基准测试中,有16项超越同类规模模型
- 匹配或超越Gemini3.0Pro等行业领导者的能力
- 在实际机器人控制场景中展现出优越性能
在仓库模拟中,使用HY-Embodied-0.5的机器人在堆叠不规则物体时比标准系统错误减少30%。其影响远不止实验室环境——想象一下能够真正整理厨房的家庭助手,或适应不可预测物品摆放的制造机器人。
未来展望
虽然仍处于早期阶段(0.5版本号暗示还有更多改进),这项技术代表着迈向真正具身AI的关键一步。随着腾讯不断完善系统,我们可能很快会看到不仅能"看见"世界,还能以接近人类流畅性的方式理解和互动世界的机器人。
关键要点
- 专用架构克服通用视觉模型的局限
- 两种配置平衡不同应用的速度与性能
- 实际表现超越当前基准
- 应用场景从物流到家用机器人
- 未来版本有望进一步缩小与人类空间推理的差距