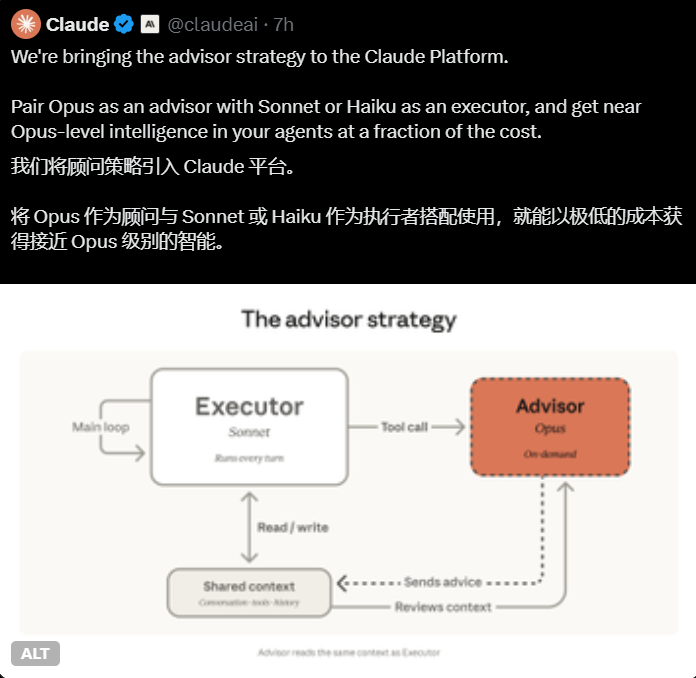
阿里巴巴微型AI模型凭借智能升级回收技术大放异彩
阿里巴巴的AI突破:以小博大的艺术
在展现惊人工程智慧的过程中,阿里巴巴国际数字商业团队推出了Marco-Mini-Instruct——这是其Marco-MoE系列的新成员,彻底颠覆了人们对AI模型规模的传统认知。这次发布的特别之处不在于模型体积,而在于它如何实现小身材大能量。

令人惊讶的效率
数据讲述了一个引人入胜的故事:虽然该模型总参数达到173亿,但运行时仅智能激活8.6亿(约5%)。这种选择性激活带来了显著的效率提升——使得模型能在普通计算机处理器上流畅运行,无需专用硬件。早期测试显示,在8位量化和四根DDR4 2400内存条的配置下,其处理速度约为每秒30个token。
升级回收的魔法
这才是最精彩的部分。研究人员没有从零开始构建,而是对现有的Qwen3-0.6B-Base模型进行了非凡的升级。他们运用所谓的'升级回收'技术,将这个普通模型转变为更强大的存在。
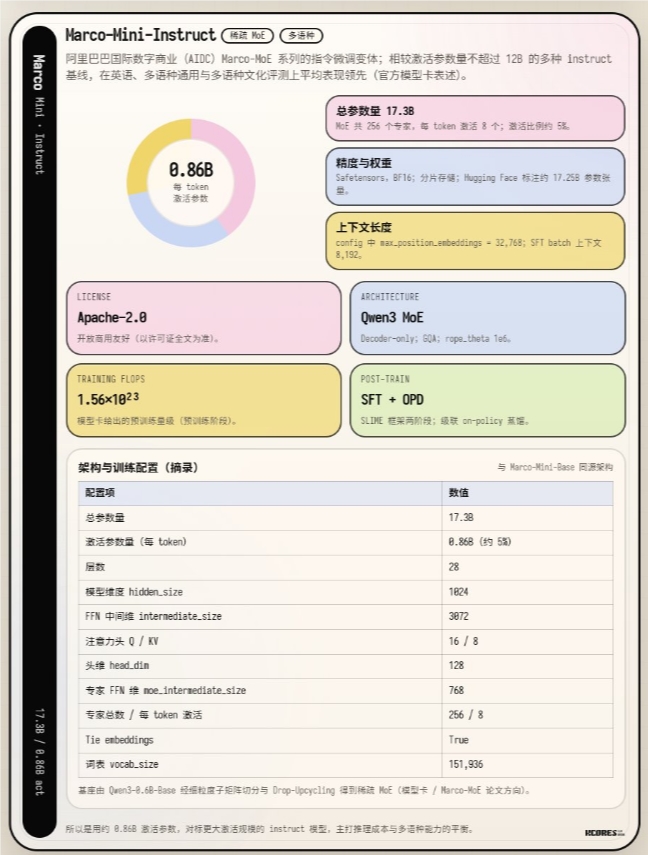
该过程包含多项精妙技巧:
- 智能分割:原始模型的部分组件被拆分或复制以创建多个专用'专家'
- 智能路由:通过机制决定针对不同任务咨询哪些专家
- 策略性舍弃:训练过程中随机忽略部分专家或路径以提高鲁棒性
这些技术的结合为从传统'密集'模型过渡到更高效的MoE(专家混合)架构提供了更平滑的路径。
充满智慧的训练
团队并未止步于结构创新。在模型'教育'方面,他们采用了级联蒸馏方法:
- 首先以强大的Qwen3-30B-A3B-Instruct模型作为教师进行初步精炼
- 随后在更先进的Qwen3-Next-80B-A3B-Instruct指导下进行高级训练
训练内容涵盖从指令遵循到复杂推理和数学能力的全方位培养,最终造就了这个实力超群的AI助手。
令人印象深刻的性能
基准测试结果验证了这一方法的有效性。尽管激活参数远少于许多竞争对手,Marco-Mini-Instruct的表现却经常超越体积数倍于它的密集模型,包括Qwen3-4B。这证明在AI领域,更智能的设计能够战胜蛮力扩展。
重要意义
这一发展为AI普及开辟了新可能。相对适中的硬件需求(不同训练阶段使用64块GPU运行24-110小时)意味着小型团队也能在没有庞大计算预算的情况下尝试MoE架构。
阿里巴巴的成果揭示了AI发展的重要一课:突破性性能并非总是来自堆叠更多参数。有时候,关键在于更聪明地利用现有资源——这一原则可能塑造下一代高效实用AI系统的未来。
核心要点:
- 资源智能AI:173亿参数模型运行时仅激活5%
- 硬件友好:在标准CPU上以约30token/秒的速度高效运行
- 创意起源:通过'升级回收'技术从小型模型改造而来
- 训练创新:采用级联蒸馏实现平衡能力
- 可及未来:降低了MoE模型开发与部署的门槛