腾讯与清华联手突破AI音乐技术,挑战行业领导者地位
腾讯与清华大学发布颠覆性AI音乐模型
AI音乐领域迎来了令人振奋的新进展。腾讯与清华大学人机语音交互实验室联合推出的SongGeneration2基础模型,正在为人工智能音乐创作树立新标杆。
解决AI音乐的最大难题
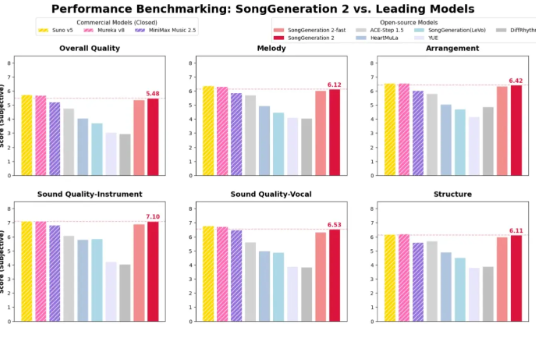
SongGeneration2的突出之处何在?它攻克了早期AI音乐系统长期存在的三大问题:
- 音乐复杂度:告别简单旋律的时代。该模型能处理复杂的多轨编排,呈现专业级的空间深度。
- 清晰人声:发音错误和音高波动?大幅减少。仅8.55%的音素错误率表现优于Suno v5(12.4%),并接近MiniMax2.5水平。
- 精准控制:无论是通过文字描述还是提供音频示例,该模型都能出色地遵循指令,实现定制化的风格和情感表达。
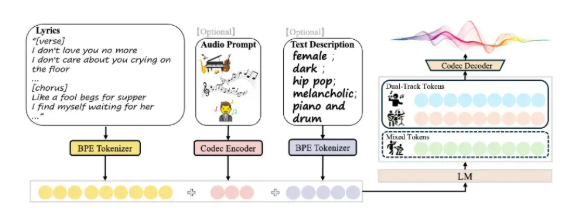
工作原理:背后的技术魔法
SongGeneration2的秘诀在于其混合架构:
- LeLM(作曲大脑):担任音乐总监角色,规划整体结构和人声细节。
- 扩散渲染器:在LeLM指导下处理复杂的声学细节。
- 并行处理:创新性地同时建模混合表示和多轨元素。
推动音乐创作民主化
令开发者振奋的是,腾讯开源了40亿参数版本(SongGeneration-v2-large)。更令人印象深刻的是?它仅需22GB显存即可在消费级硬件上流畅运行——让家庭用户也能触及专业级音乐创作门槛。
对于追求即时效果的用户,HuggingFace上提供了SongGeneration-v2-Fast版本——以轻微质量妥协为代价,可在不到一分钟内生成完整歌曲。
随着这些工具日益普及,我们正见证AI音乐从技术演示向实用工具的转变——这可能彻底改变我们创作和体验音乐的方式。
核心要点:
- 新型LLM-扩散混合架构树立性能标杆
- 语音准确度超越众多商业竞争对手(8.55% PER)
- 开源方式降低创作者入门门槛
- 高效运行于消费级硬件(22GB显存)
- 快速版可在60秒内生成完整歌曲