腾讯AI Lab开发Parallel-R1框架以增强推理能力
腾讯AI Lab发布突破性并行思维框架
随着人工智能的快速发展,研究人员日益关注提升大语言模型的推理能力。腾讯AI Lab与学术合作伙伴共同开发了Parallel-R1——一种新型强化学习框架,旨在教会AI系统并行思维能力,即同时探索多种解决路径。
解决传统方法的局限性
当前方法通常依赖监督微调(SFT),存在显著缺陷:
- 严重依赖高质量训练数据
- 倾向于模仿而非自主推理
- 泛化能力有限

Parallel-R1框架通过以下创新方案应对这些挑战:
- 简易提示生成基础数学问题的并行思维数据
- 渐进式课程训练模型逐步构建复杂度
- 培养真正问题解决能力的强化学习技术
Parallel-R1背后的技术创新
研究团队实现了多项突破性技术:
渐进式学习方法
模型首先通过基础问题掌握并行思维语法,再进阶到复杂数学挑战。
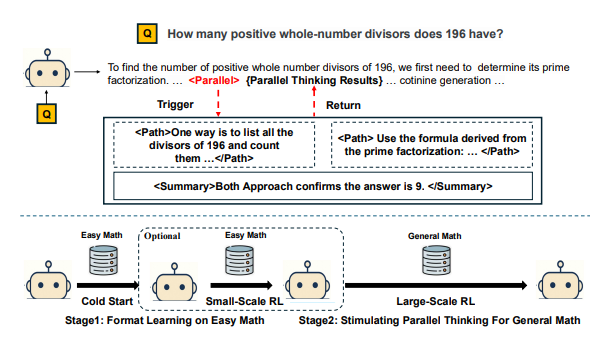
双重奖励策略
系统采用交替奖励机制平衡:
- 准确性奖励用于正确解决方案
- 多样性奖励鼓励并行路径探索 这种双重策略显著提升了精确度和创造性问题解决能力。
已证实的性能提升
实验结果展示显著进步:
| 基准测试 | 改进幅度 |
|---|
该框架还展示了推理策略的演变过程——从训练初期的广泛探索转变为训练后的精确验证方法。
未来影响
Parallel-R1的成功为以下领域开辟新可能:
- AI系统中复杂问题解决的增强
- 数学推理任务的新方法
- 需要多路径分析的更广泛应用场景 这项突破凸显了并行思维的潜力,研究人员将继续推动人工智能能力的边界。
关键要点:
- 腾讯Parallel-R1支持同时探索多条推理路径
- 框架克服了传统监督微调的局限性
- 渐进式训练和双重奖励带来显著性能提升
- 在高级数学基准测试中实现高达42.9%的改进
- 代表AI推理方法论的重大进步