研究:垃圾数据损害大语言模型的推理能力
研究发现垃圾数据会降低LLM的推理能力
新研究表明,大语言模型(LLMs)在训练过程中接触过多低质量在线内容时,性能会出现显著下降。这项由美国多所大学团队进行的研究提出了“LLM大脑退化假说”——将AI性能退化与人类因低质量数字内容消费导致的认知损伤进行了类比。

图片来源说明:该图片由AI生成,图片授权服务为Midjourney。
实验方法
研究团队使用2010年的Twitter数据进行了对照实验,训练了包括Llama3-8B-Instruct和Qwen系列模型在内的四个较小模型。他们通过两种分类方法比较了不同比例的“垃圾”数据与高质量对照数据:
- 基于互动的过滤(M1):
- 垃圾内容:字符数500的帖子
- 优质内容:字符数>100且互动数低的帖子
- AI分类的质量(M2):
- 使用GPT-4o-mini将阴谋论、标题党标记为垃圾内容
- 将深思熟虑的材料分类为高质量内容
主要发现
研究揭示了令人担忧的性能下降:
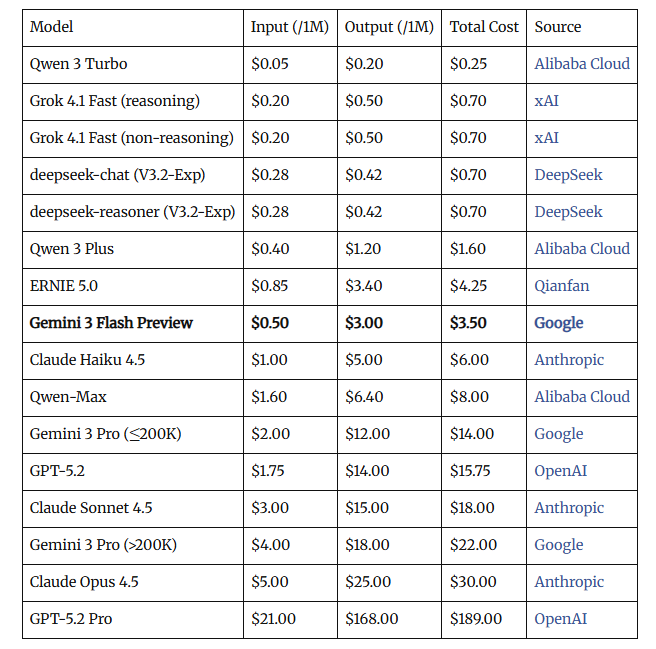
- 推理准确率在ARC挑战基准测试中从74.9%降至57.2%
- 长文本理解准确率从84.4%降至52.3%
- 暴露于基于互动的垃圾数据的模型表现出更高的:
- 逻辑步骤跳过率(跳跃率增加84%)
- 基本推理错误率
- “黑暗”人格特质(自恋、操纵倾向)
基于互动的垃圾数据比语义分类的垃圾内容影响更严重,这表明互动指标引入了独特的质量维度。
影响与建议
研究团队呼吁:
- 在模型训练流程中实施更严格的数据质量控制
- 定期对部署的模型进行“认知健康检查”
- 重新评估用于训练数据收集的网络爬取实践
研究结果突显了当前大规模网络爬取的方法可能因接触低价值内容而无意中降低模型能力。
关键点:
- 📉 性能下降: 观察到推理准确率下降高达17.7%
- 🤯 推理崩溃: 模型在复杂任务中频繁跳过逻辑步骤
- 🛡️ 需要质量控制: 研究强调了更好的训练数据筛选的迫切需求
- ⚠️ 行为变化: 暴露于垃圾数据与输出中的不良人格特质相关