DeepSeek发布新AI模型挑战科技巨头
DeepSeek双AI模型发布实现技术升级
AI研究界刚刚获得了令人兴奋的新工具。DeepSeek发布了其旗舰模型的3.2版本,为大型科技公司的闭源替代方案带来了强劲竞争。
两款模型,双重影响
该公司推出了两个变体:
- V3.2标准版:处理长达128,000单词的文档时,与OpenAI的GPT-5性能不相上下
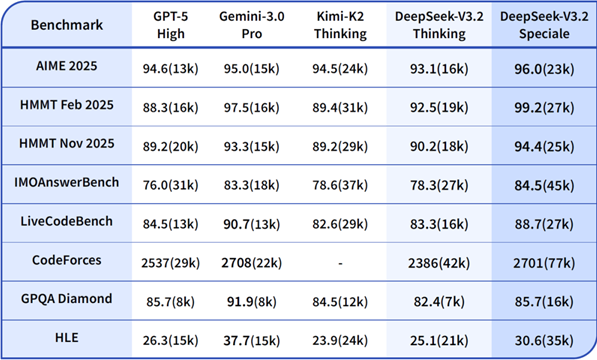
- V3.2-Speciale:在学术基准测试中与Google的Gemini3Pro匹敌,同时能生成更详细的答案
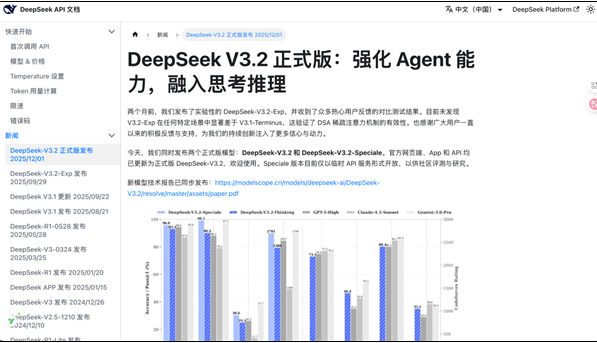
底层技术突破
秘密武器?一项名为Directory-Style Attention(DSA)的巧妙创新。传统AI模型在处理长文档时存在困难,因为处理时间会随长度呈指数级增长。DSA彻底改变了这一状况:
- 使处理时间呈线性而非指数级增长
- 内存使用减少40%
- 推理速度提升2.2倍
结果如何?这是首个能在单张显卡上处理百万token文档的开源模型。
通过优化训练实现更智能的思考
DeepSeek团队在训练上也毫不妥协:
- 专门将超过10%的计算能力用于强化学习
- 采用基于群体的强化学习(GRPO)结合多数投票机制
- 移除了抑制长推理链的人工限制
测试结果证明了这些努力的价值——Speciale生成的答案不仅更长(比Gemini3Pro多32%的token),而且更准确(高出4.8个百分点)。
持续践行开源承诺
两款模型现已以商业友好的Apache 2.0许可证发布在GitHub和Hugging Face上。DeepSeek承诺将进一步开放: "我们计划接下来发布DSA内核和RL训练框架,"公司发言人表示。
此举延续了DeepSeek将专有优势转化为社区资产的战略——如果他们保持这一发展速度,到2026年可能会重塑竞争格局。
关键要点:
- 性能相当:在各自领域达到与GPT-5/Gemini3Pro同等能力
- 技术创新:DSA实现高效的百万token处理
- 训练投入:投入大量计算资源进行RL优化
- 开放理念:完整权重以Apache 2.0许可证商业可用