机器人通过新型GeoVLA框架获得3D视觉能力
机器人终于能像人类一样看世界了

想象一下蒙着眼睛在厨房里摸索——这基本上就是当今机器人感知世界的方式。尽管人工智能取得了巨大进步,但大多数机器人视觉系统仍难以掌握基本的空间意识。当前诸如OpenVLA和RT-2等视觉-语言-动作(VLA)模型依赖平面的二维图像,使其本质上无法感知深度和位置。
这种局限在非结构化环境中尤为明显——当深度感知至关重要时。设想一个机械臂试图抓取拥挤桌面上的杯子:若无法理解物体的远近关系,简单任务就会变成令人沮丧的试错过程。
三维感知的突破
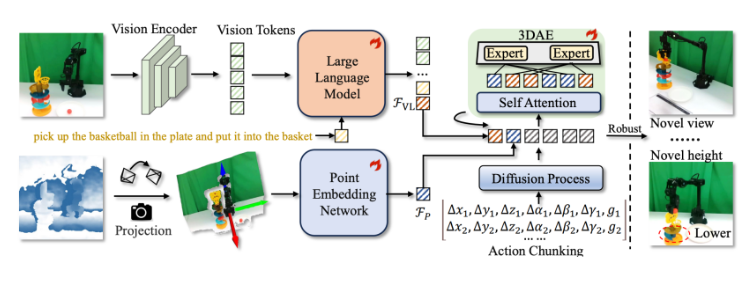
月立灵机研究团队开发出了机器人梦寐以求的"智能眼镜"。他们的GeoVLA框架通过两项创新组件实现了真正的3D感知:
- 点云嵌入网络(PEN): 像人类大脑解析深度线索那样处理空间数据
- 空间感知动作专家(3DAE): 将空间理解转化为精确动作
"我们本质上为机器人补全了缺失的维度,"项目首席研究员孙林博士解释道,"现有系统看到的是平面图片,而GeoVLA构建的是空间心智模型——不仅能识别物体,还能理解它们在三维空间中的实际位置。"
深度感知实测表现
测试结果充分证明了新方法的优越性:
- LIBERO基准测试97.7%成功率(超越先前所有模型)
- 在ManiSkill2仿真中处理复杂物体的卓越能力
- 对意外场景和视角变化的惊人适应性
关键在于GeoVLA的任务分离设计:传统视觉语言模型负责物体识别,而专用组件则处理空间推理和运动规划。
对机器人技术的深远影响
这项技术的应用前景远超实验室演示:
- 可可靠处理不规则零件的工业机械臂
- 能在杂乱家居环境中安全行动的家庭助手
- 更准确理解坍塌结构的搜救机器人
研究团队已将成果公开,邀请全球机器人社区共同推进发展。
核心要点:
- 问题: 现有机器人视觉缺乏深度感知
- 解决方案: GeoVLA通过双流架构实现真三维理解
- 组件构成: PEN负责空间映射 + 3DAE负责运动规划
- 成果: 受控测试接近完美表现,具备强大现实应用潜力
- 获取方式: 可通过项目网站获取框架


