OpenAudio发布S1-Mini:一款轻量级开源TTS模型
随着Fish Audio开发的OpenAudio S1-Mini这一开源文本转语音(TTS)模型的发布,AI语音技术领域获得了一个强大的新工具。作为广受好评的S1模型的轻量级版本,它在资源受限的环境中提供了专业级的语音合成能力,同时保持了令人印象深刻的性能。
小巧包装中的技术突破
从拥有40亿参数的前代模型蒸馏而来,S1-Mini仅用5亿参数运行——这一显著缩减使其适用于边缘设备和本地应用。尽管体积更小,该模型并未在质量上妥协。基于超过200万小时的音频数据训练,它支持包括中文、英文、日文和法文在内的14种语言。
让S1-Mini脱颖而出的是其情感范围。该模型能生成超过50种声音表达类型,从愤怒、快乐到笑声和哭泣声。这些能力产生了极易被误认为真实录音的类人语音。
普及语音技术
开源S1-Mini的决定代表了一项降低AI语音开发门槛的战略举措。该模型可在Hugging Face免费下载(遵循非商业使用条款),为小型团队和独立开发者提供了以往需要昂贵订阅才能获得的技术访问权。
OpenAudio还推出了一个在线演示平台,让潜在用户能亲身体验模型的能力。这种透明度既建立了社区信任,又鼓励了对技术的协作改进。
具有竞争力的性能指标
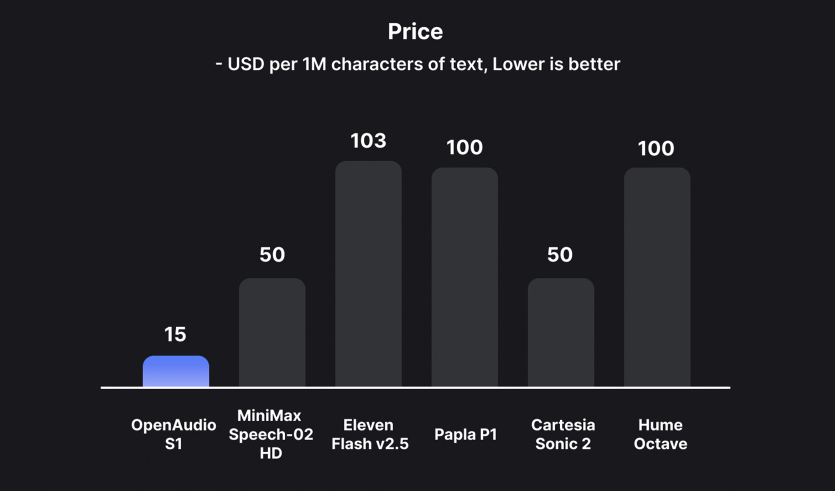
在Hugging Face的TTS Arena等平台上进行的独立测试显示,S1-Mini与来自ElevenLabs和OpenAI的商业产品相比毫不逊色。该模型的秘密武器是其采用了人类反馈强化学习(RLHF),从而微调输出以实现自然的流畅度和情感真实性。
虽然目前仅限于非商业用途,但S1-Mini为学术研究和个人项目提供了巨大价值——尤其是在其表现出色的多语言应用中。
跨行业的多样化应用
教育领域可以利用S1-Mini开发语言学习工具,而媒体制作人可能会将其用于有声书旁白或播客生成。互动应用将受益于其特殊效果能力,如笑声或喊叫——这些功能为虚拟角色增添了深度感。
由于对非英语语言的强大支持,全球采用前景看好。这使S1-Mini成为现有TTS解决方案服务不足市场的潜在颠覆者。
未来发展
Fish Audio计划持续改进S1-Mini,包括扩展语言支持和潜在的实时应用版本。随着开源社区对其开发的贡献,该模型可能挑战商业TTS垄断并推动整个行业的创新。
项目地址:https://huggingface.co/fishaudio/openaudio-s1-mini
关键点
- OpenAudio S1-Mini仅用5亿参数即可提供高质量的TTS
- 支持14种语言和超过50种情感声音表达
- 作为免费开源软件在Hugging Face提供(非商业用途)
- 在自然度测试中优于部分商业模型
- 潜在应用涵盖教育、娱乐和互动媒体