OpenAI加强ChatGPT安全防护,抵御隐蔽提示攻击
OpenAI收紧ChatGPT的安全防线
在AI助手日常浏览网页并与外部应用交互的时代,OpenAI正在加强ChatGPT防御日益复杂的攻击。该公司最近推出了两项重要的安全增强功能,旨在保护用户免受提示注入漏洞的影响——随着AI系统互联程度提高,这一问题愈发令人担忧。
锁定模式:敏感对话的坚固堡垒
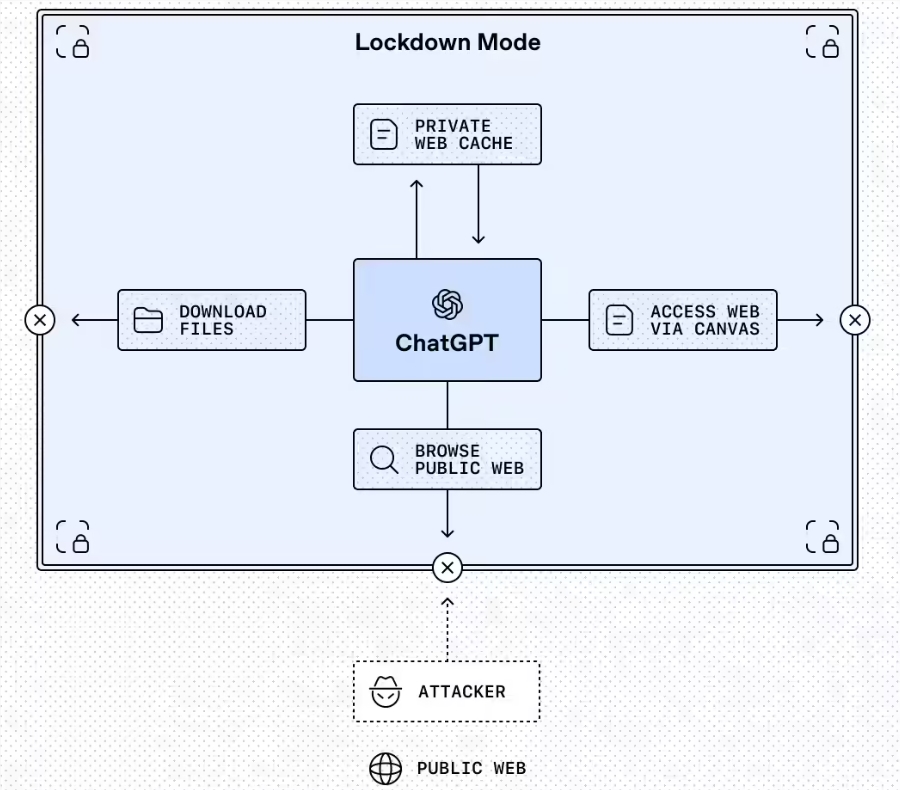
首个创新功能名为锁定模式,如同为高风险交互打造的数字安全屋。目前该可选设置面向企业、教育、医疗和教师版本开放,严格限制ChatGPT与外部系统的通信方式。可以想象成在讨论机密信息时暂时关闭所有门窗。
"我们专为数据安全不容妥协的场景设计了锁定模式,"OpenAI发言人解释道。激活后该模式将:
- 仅允许浏览缓存内容
- 自动禁用缺乏可靠安全保障的功能
- 允许管理员微调许可应用列表
这些控制并非简单的开关切换。组织管理员可创建自定义角色,精确指定锁定期间仍可用的操作。令人惊讶的是该系统甚至提供完美的合规日志用于监管审计——医疗和金融机构的必备功能。
高风险功能新增警示标签
第二项措施在整个ChatGPT生态系统(包括Atlas和Codex)引入标准化"高风险"标签。这些视觉警示会突出显示虽然实用但具有更高安全隐患的功能。
"某些能力确实能提升生产力但需权衡利弊,"OpenAI安全团队指出。这些标签充当明确路标,尤其在处理私人数据或启用网络访问功能时更为重要。
警告不仅限于红色警示灯。每个标记功能包含:
- 潜在风险的简明解释
- 推荐使用场景
- 实用缓解策略
- 激活后变化的明确指示器
为何此时推出这些改变
此次更新正值提示注入攻击日趋复杂之际。黑客已发现可通过在看似无害的提示中嵌入恶意命令来操纵AI系统——可能触发未授权操作或数据泄露。
OpenAI的方案结合了主动限制(锁定模式)与透明沟通(风险标签)。虽然消费者版本将很快获得访问权限,企业客户现已享受这些保护措施。
这些举措表明随着其模型成为职场标配而非仅是对话奇技,OpenAI对安全的重视程度非同一般。
关键要点:
- 锁定模式严格限制敏感用例的外部交互
- 高风险标签清晰警示潜在危险功能
- 两项措施均建立在现有沙盒和URL保护系统基础上
- 企业/教育版本优先于消费者版本获得更新
- 应对日益增长的提示注入漏洞担忧