Moonshot的Kimi线性模型大幅提升AI处理速度
Moonshot的Kimi线性模型革新AI处理
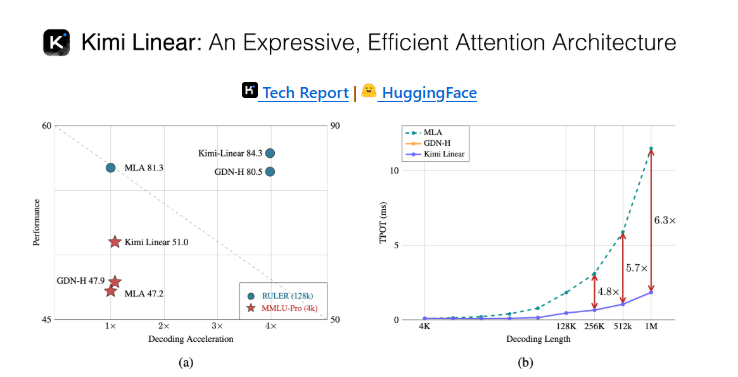
在人工智能生成内容(AIGC)领域的重大突破中,Moonshot发布了Kimi Linear模型,带来了前所未有的效率提升。该模型处理长上下文的速度比传统系统快2.9倍,解码信息快6倍,解决了AI性能中的关键瓶颈。
突破传统限制
传统的Transformer模型依赖Softmax注意力机制,其O(n²)的计算复杂度导致资源需求呈指数级增长,严重限制了实际应用,尤其是在处理长文本时。Kimi Linear的突破在于其线性注意力方法,将复杂度降低至O(n),同时保持高精度。
创新架构:KDA与Moonlight
该模型的核心创新是Kimi Delta Attention(KDA)机制,它引入了细粒度的门控系统来动态管理内存状态。KDA优化了信息保留与遗忘机制,这对于长时间交互至关重要。
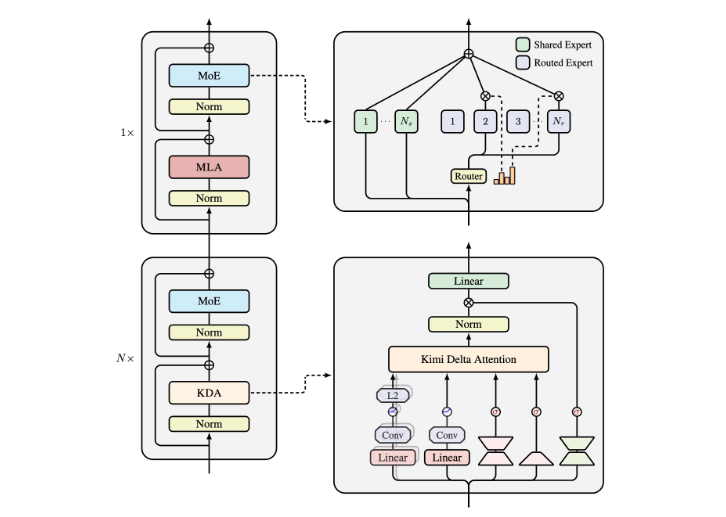
与KDA相辅相成的是Moonlight架构,它以3:1的比例将KDA与全注意力层结合。这种混合设计在计算效率和强大的模型能力之间取得了平衡,特别擅长需要大量上下文记忆的任务。
已验证的性能优势
实验结果凸显了Kimi Linear的卓越性能:
- 回文任务:通过精确的长上下文处理提高了准确性。
- 多查询关联召回:在复杂检索场景中表现优异。
该模型的效率为实时AIGC应用开辟了新可能,从自动化内容生成到高级强化学习系统。
关键点:
- 🚀 长上下文处理速度提升2.9倍,解码速度提高6倍。
- 🔧 Kimi Delta Attention(KDA)通过动态门控优化内存管理。
- ⚖️ 3:1混合架构确保速度与精度的最佳平衡。
