Mistral AI全新Small4模型:开发者的瑞士军刀
Mistral AI通过Small4发布树立新标杆
在快速发展的开源AI领域,总部位于巴黎的Mistral AI迈出了重要一步。他们新推出的Small4模型不仅是渐进式更新——更是开发者期待已久的真正通用工具,无需做出痛苦妥协。
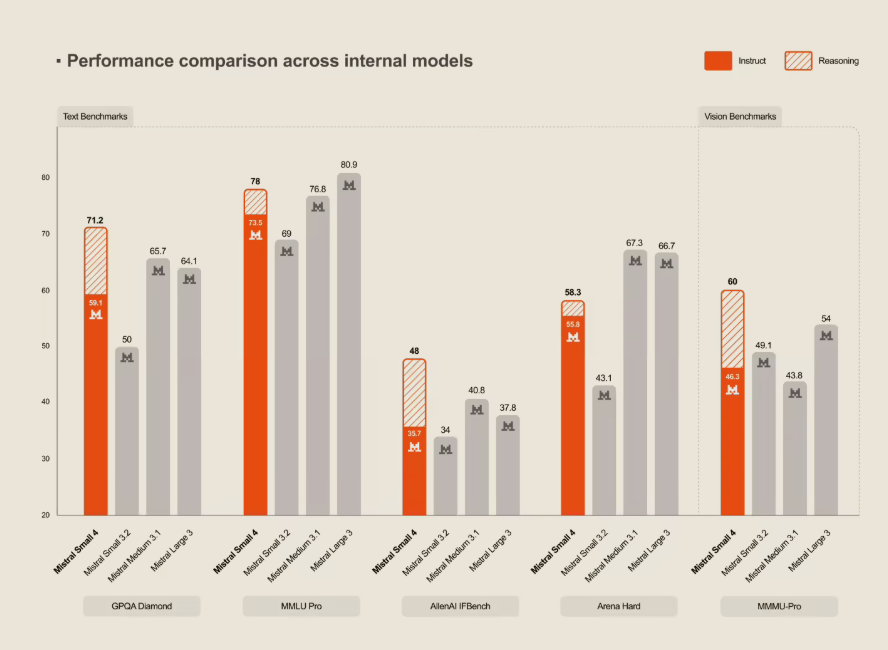
打破专业化取舍困境
多年来开发者面临艰难选择:要么选择擅长单一任务(如编程)但其他能力薄弱的模型,要么接受平庸的综合表现。Small4通过以下特性改变了这一局面:
- 旗舰级推理能力 媲美专有模型
- 多模态理解 可处理文本、图像等多种输入
- 编程实力 能驾驭复杂代码库
秘诀何在?创新的MoE(专家混合)架构仅针对特定任务激活其1190亿总参数中的60亿。这意味着您能获得顶级性能,却无需为不必要的计算开销买单。
切实有效的实践优势
实际应用中这意味着什么?想象您可以:
- 处理长达数百页的技术文档(得益于巨大的256k上下文窗口)
- 执行需要深度代码理解的复杂编程任务
- 开展融合文本与视觉元素的多模态项目
所有这些都无需在不同专用模型间切换。效率提升同样显著——在延迟优化模式下,Small4完成任务速度比前代快40%;当吞吐量至关重要时,每秒处理的请求量可达三倍之多。
最佳性能的硬件考量
为充分发挥Small4性能,Mistral建议:
- 最低配置: 4× HGX H100或1× DGX B200 GPU
- 推荐配置: 4× HGX H200或2× DGX B200组合方案
具体选择取决于您侧重成本效益还是峰值性能的需求。
本次发布的重要意义
科技界对Mistral坚持开源理念(Apache 2.0许可证)与尖端技术结合的做法反响热烈。在包括OpenAI产品在内的基准测试中,Small4表现出色且仍向全球开发者完全开放。
随着AI应用日益复杂且相互关联,像Small4这样消除专业化取舍的工具将愈发珍贵。这不仅是又一次模型发布——更预示着我们AI工具即将达到的多功能境界。
核心要点:
- Mistral首个真正通用模型 整合推理、多模态与编程能力
- MoE架构(1190亿总参数/60亿活跃参数)平衡性能与效率
- 256k上下文窗口 处理大型文档和代码库
- 延迟模式下比前代快40%
- 采用Apache 2.0许可证开源