Mistral AI新模型:小体积蕴含大性能
Mistral AI通过高效开源模型再升级
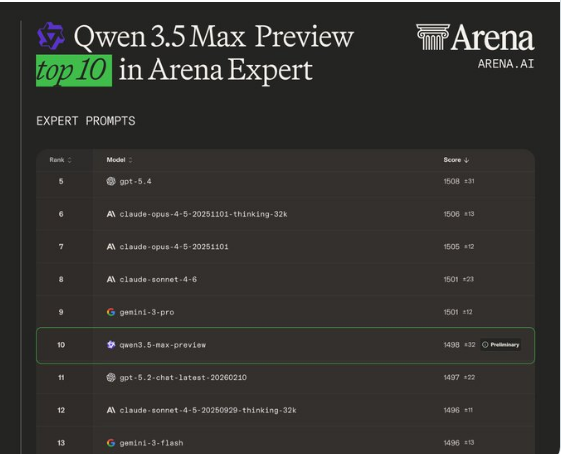
法国AI独角兽Mistral在12月2日发布的Mistral3系列引发广泛关注。此次发布延续了该公司提供强大且高效开源模型的传统,同时带来了一些重大升级。
小体积,大能力
新系列包含三个密集模型(3B、8B和14B参数)以及旗舰产品Mistral Large3。这些模型的特别之处在于?它们在保持Mistral标志性效率的同时,将上下文长度扩展至惊人的128K tokens——非常适合处理长文档或复杂对话。
 图片来源说明:该图片由AI生成,图片授权服务提供商为Midjourney。
图片来源说明:该图片由AI生成,图片授权服务提供商为Midjourney。
令人惊喜的性能表现
基准测试结果颇具启发性。在MMLU、HumanEval和MT-Bench等标准测试中,Mistral3模型的表现至少不逊于——有时甚至优于——同级别的Llama3.1版本。秘诀何在?一种巧妙结合滑动窗口注意力与分组查询注意力的混合架构。
"我们专注于实际可用性,"公司发言人解释道,"14B版本可以在单个A100 GPU上处理完整的128K上下文推理,同时将批量场景吞吐量提高42%。"
跨行业的实际效益
其影响十分显著:
- 研究人员能够经济实惠地使用强大工具
- 企业无需庞大基础设施即可部署高性能AI
- 教育工作者获得新的内容创作可能性
所有模型均采用Apache 2.0许可发布,意味着权重已在Hugging Face和GitHub上开放供个人和商业使用。
关键要点:
- 三种模型尺寸(3B/8B/14B)外加旗舰Large3变体
- 128K上下文窗口高效处理复杂任务
- 仅需单个A100运行使部署异常便捷
- 开源许可消除商业障碍
- 基准测试表现匹配或超越同类模型