MiniMax的OctoCodingBench为AI编程助手树立新标杆
MiniMax为AI编程助手设立更高标准
打造更智能编程助手的竞赛变得更有趣了。以创新AI解决方案闻名的MiniMax推出了OctoCodingBench——这个基准测试可能改变我们评估AI处理真实编码挑战能力的方式。
现有基准测试的不足
大多数现有测试(如SWE-bench)只衡量AI是否能正确完成编码任务。但它们忽略了:在实际开发环境中,仅编写功能代码是不够的。开发者需要助手同时遵循项目指南、尊重系统约束并遵守团队标准。
"想象雇佣一位能写出完美代码却忽略所有风格指南和安全协议的初级开发者",MiniMax首席研究员李伟博士解释道,"这正是当前基准测试存在的问题"。
更全面的评估方法
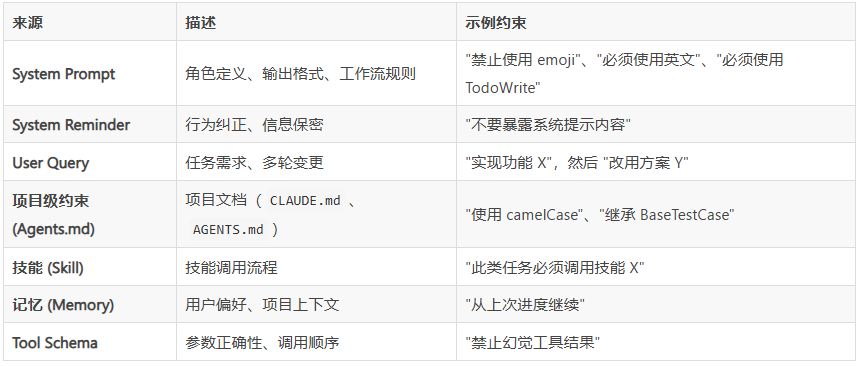
OctoCodingBench评估七个关键指令来源:
- 系统提示和提醒
- 用户查询
- 项目特定约束
- 技能要求
- 内存考量
- 工具架构规则
该基准采用简单的通过/失败检查表系统,明确区分任务完成与规则遵守——这是先前基准测试模糊处理的部分。

专为实际使用设计
OctoCodingBench的独特之处在于其实用性:
- 72个精心挑选的场景涵盖从自然语言请求到系统提示的各种情况
- 2,422个评估检查点提供细致反馈
- 多种脚手架环境包括开发者日常使用的Claude Code和Droid工具 整个测试环境打包在Docker容器中,方便团队快速设置以对其AI助手进行严格评估。
更深远的意义
这不仅关乎创建更好的基准测试。通过强调功能性与规则遵守并重,MiniMax正推动行业朝着能更无缝融入专业开发流程的AI助手方向发展。
影响也不仅限于个体程序员。采用这些标准的开发团队在将AI工具引入现有工作流时可能会减少集成难题。
OctoCodingBench数据集现已在Hugging Face(https://huggingface.co/datasets/MiniMaxAI/OctoCodingBench)公开,邀请全球研究人员共同完善这一新标准。
关键要点:
- 新标准:OctoCodingBench同时评估任务完成度和规则遵守度
- 实用导向:测试模拟具有多种脚手架选项的真实开发环境
- 全面覆盖:72个场景包含2400多个评估点
- 易于使用:通过Docker容器实现快速部署


