MiniMax与华中科技大学开源颠覆性视觉AI技术
视觉AI迎来重大升级却无需成长阵痛
在人工智能研究领域掀起波澜的行动中,MiniMax与华中科技大学合作将VTP(视觉分词器预训练)技术作为开源项目发布。这一发展的非凡之处在于:它在保持核心Diffusion Transformer(DiT)架构不变的情况下,实现了图像生成质量65.8%的惊人提升。
改变游戏规则的分词器
想象通过改进变速箱而非增加马力来提升汽车性能——这正是VTP为视觉AI系统带来的变革。传统方法如DALL·E3和Stable Diffusion3专注于扩大主神经网络规模,而VTP则选择了一条更智能的道路:优化图像转换为AI理解语言的方式。
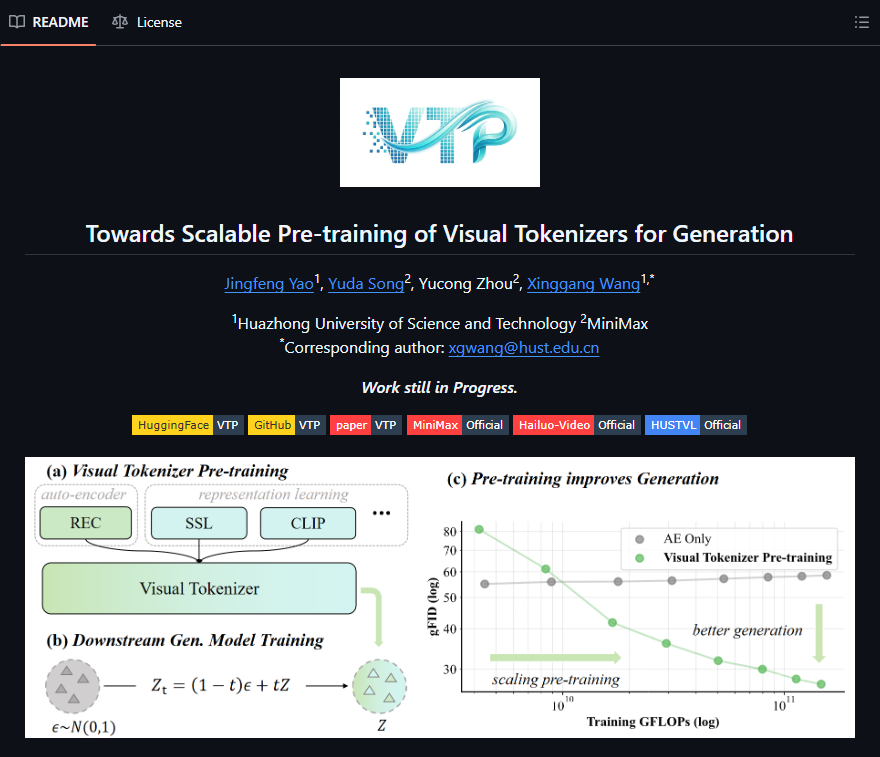
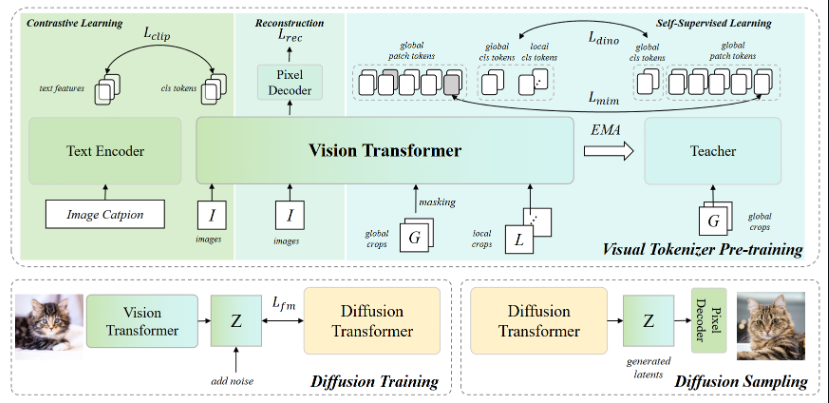
VTP的秘诀在于预训练阶段创建更优质的"视觉词典"。这些优化的分词器生成的表征使下游系统更易处理,有效释放现有DiT模型的超常潜力。
不仅是数字的提升
VTP不仅代表渐进式改进——它标志着我们思考AI能力扩展方式的根本转变:
- 首次建立将分词器质量直接关联生成表现的理论框架
- 展示类似模型规模扩展中的"分词器缩放"定律
- 在无止境的参数竞赛之外开辟新效率前沿
其影响深远。未来进步可能来自更智能的预处理而非持续增长的算力需求——这或将 democratizing高品质视觉AI技术。
开源扩大影响力
研究团队并未封锁这项突破。他们完整发布了代码、预训练模型和训练方法论——确保与现有DiT实现的兼容性。这意味着小型团队也有望取得媲美大型竞争对手的成果。
在行业焦点从纯粹规模转向系统级效率之际,此刻开源恰逢其时。VTP证明了精心设计的工程方案有时能胜过蛮力计算。
关键要点:
- 66%提升仅通过分词器优化实现
- 无需修改DiT——兼容现有实现
- 完全开源降低采用门槛
- 挑战性能增益来源的传统认知
- 潜在范式转变指向更高效的AI发展路径