微软全新开源语音模型:思考速度般的实时对话体验
微软语音突破:实现对话级响应速度的AI
微软近期突然发布VibeVoice-Realtime-0.5B,这款开源文本转语音模型的响应速度让人感觉像在与真人而非软件对话。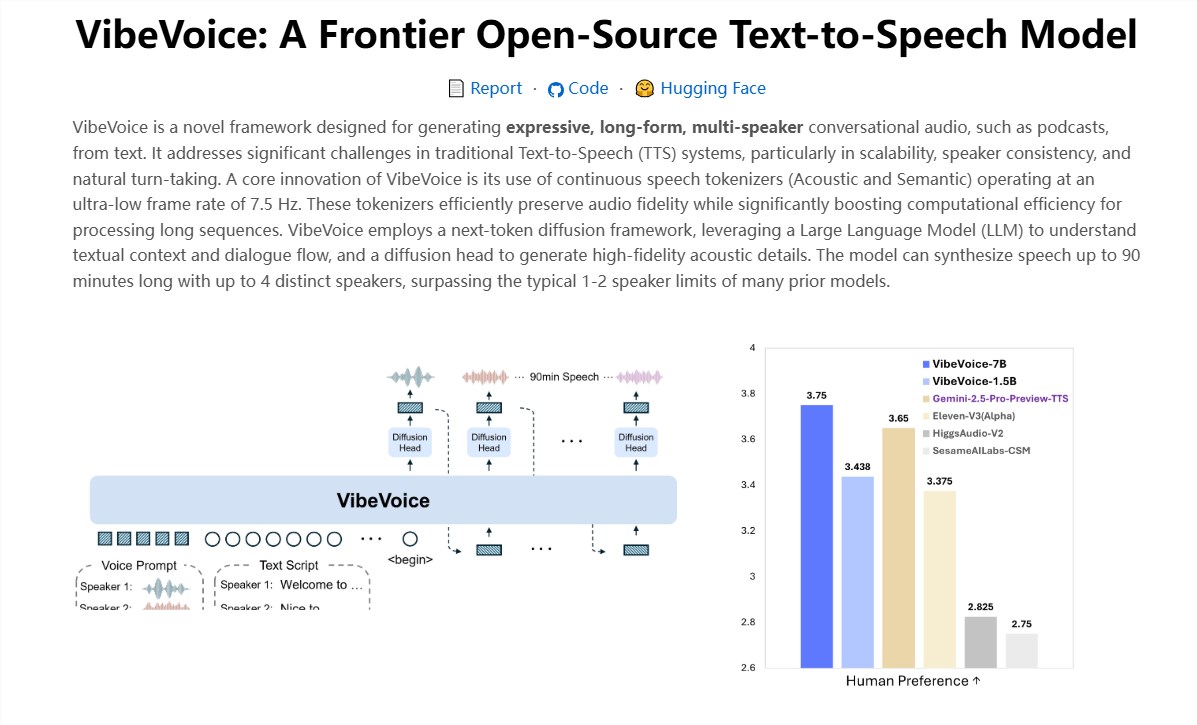
眨眼即逝的极速响应
该模型最惊人的是其300毫秒响应时间。相较传统TTS系统1-3秒的延迟(足以让人怀疑输入内容),VibeVoice能在你思考完成前就开始发声。早期测试者形容体验"诡异"——就像有个超速阅读者站在你身后。
马拉松式表现
别被其小巧体型迷惑(仅5亿参数)。它能连续生成90分钟无机械卡顿的流畅音频,社区成员已用《三体》等硬核科幻章节进行压力测试,模型全程保持稳定输出。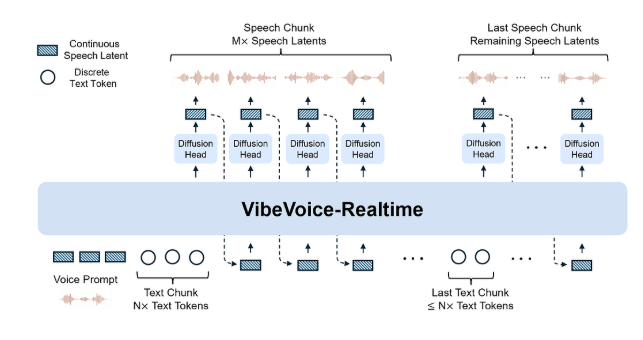
四重奏专家
VibeVoice真正惊艳之处在于能同时驾驭四种角色声线,就像主持AI晚宴。想象一个播客场景:主持人保持镇定,一位嘉宾情绪激动,另一位插科打诨,第三位偶尔道歉修正——所有声音过渡自然,毫无混乱或情绪断层。
情绪智商
模型不仅朗读文字,更能理解语境。遇到"我很抱歉"会自动转为歉疚语气;读到"太神奇了!"立即活力满满。连"我非常生气"这类细微表达也会触发相应声调变化(音调降低/语速加快),无需人工标注。
改进空间
虽然英文表现媲美商业产品,中文版本对多音字和轻声处理仍有不足。微软承诺将很快推出中国优化版。
意外轻量化
尽管性能强大,VibeVoice仅需不到2GB显存,在普通笔记本上即可实时运行。开发者已将其嵌入本地AI助手和实时翻译应用等各种场景。
该模型现以MIT许可证登陆HuggingFace和GitHub(可商用),有望成为离线应用的标配语音方案。已有用户将其与大语言模型结合打造端到端对话系统,或为通讯应用开发"即输即说"工具。
核心亮点:
- 闪电响应: 300毫秒延迟实现自然对话感
- 耐力王者: 90分钟连续朗读零失误
- 社交达人: 同步处理四种独立声线
- 情绪感知: 自动识别并表达文本情感
- 设备友好: 低资源消耗适配笔记本和边缘设备