微软BioEmu模型革新蛋白质模拟技术
微软发布突破性BioEmu蛋白质模拟模型
在一项里程碑式的公告中,微软CEO萨提亚·纳德拉揭示了BioEmu模型——这个革命性AI系统将蛋白质动态模拟时间从数年缩短至几小时。此项进展将彻底改变药物研发模式并加速个性化医疗发展。
生物研究的飞跃进步
这项发表于顶级期刊《自然》的研究,标志着计算生物学领域的重大跨越。与耗时昂贵的传统方法(如X射线晶体学和核磁共振)不同,BioEmu能提供快速且高精度的模拟。虽然谷歌的AlphaFold2擅长预测单一蛋白质结构,但在模拟动态构象方面存在不足——这正是BioEmu有效填补的技术空白。
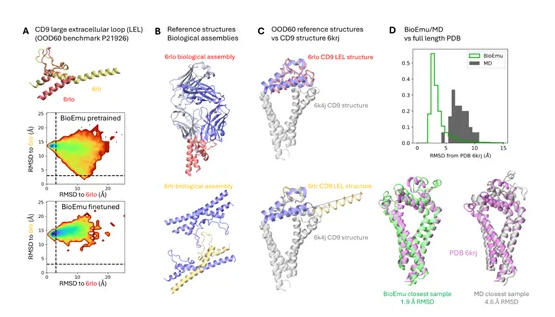
BioEmu工作原理
该模型的核心创新在于将蛋白质序列转化为多样化的3D结构:
- 基于AlphaFold2预训练模型的蛋白质序列编码器
- 在保留关键结构细节的同时降低计算复杂度的粗粒度方法
- 通过系统性消除噪声生成蛋白质构象的扩散条件生成模型
系统采用精密的评分模型来确保整个模拟过程的准确性与稳定性。
训练与数据整合
BioEmu的卓越效能源于其全面的训练策略:
- 整合超过200毫秒的分子动力学模拟数据
- 利用蛋白质稳定性数据的实验测量结果
- 实施增强模型可靠性的多阶段训练方案
这种稳健的方法论使BioEmu能以空前精度捕捉蛋白质的动态行为。
对医疗与科研的影响
此项突破的影响远超学术范畴:
- 药物开发:显著缩短新药上市时间
- 个性化医疗:实现基于个体蛋白特征的快速治疗方案定制
- 研究效率:使科学家摆脱冗长模拟过程,专注于创新研究
- 成本降低:为小型研究机构降低准入门槛
- 疾病认知:为研究阿尔茨海默症和帕金森病等蛋白相关疾病提供新工具
科学界普遍认为这是生物技术领域的变革性突破。
核心要点:
- ⚡ 速度突破:将蛋白质模拟从数年压缩至数小时
- 🔍 全面建模:克服传统方法与AlphaFold2的局限性
- 🧠 先进架构:融合序列编码、粗粒度方法和扩散模型
- 📊 数据驱动:基于大量分子动力学与稳定性数据训练
- 💊 医疗影响:加速药物发现与个性化治疗开发
