微软论文无意中揭示AI模型参数
微软论文揭示AI模型参数
微软于12月26日发布的一篇研究论文无意中披露了多个大型语言模型的参数大小,包括OpenAI和Anthropic开发的模型。这一揭示引发了关于模型架构和技术能力的讨论,特别是与医疗AI评估相关的讨论。
根据论文中详细的研究结果,OpenAI的o1-preview模型拥有大约3000亿参数,而其GPT-4o模型包含约2000亿参数。值得注意的是,GPT-4o-mini变种报告仅有80亿参数。这与Nvidia之前声称的GPT-4模型采用的1.76万亿MoE架构形成了鲜明对比。论文还指出,Anthropic的Claude3.5Sonnet模型大约有1750亿参数。

这并不是微软首次在其出版物中披露模型参数。十月份,该公司透露GPT-3.5-Turbo模型由200亿参数组成,尽管此信息后来在更新中被删除。这种反复的披露引发了业内人士的猜测,认为这些泄露是故意的还是只是疏忽。
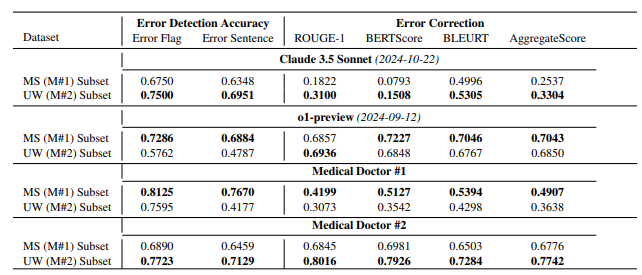
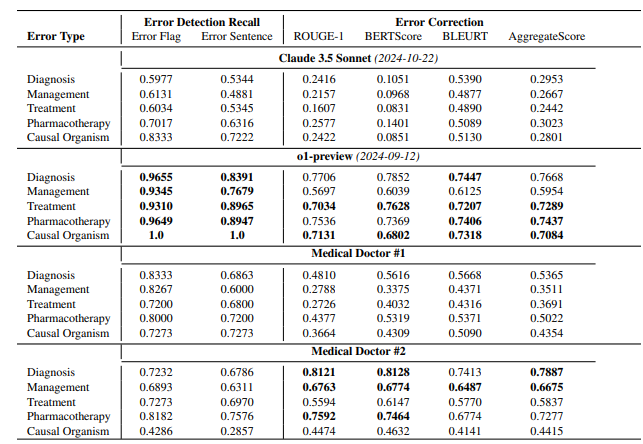
该论文的主要重点是介绍一个医疗领域基准测试,称为MEDEC。研究团队分析了来自美国三家医院的488份临床记录,以评估各种模型在识别和纠正医疗文件中的错误方面的能力。结果显示,Claude3.5Sonnet在错误检测方面优于其竞争对手,得分为70.16。

所披露数据的真实性引发了业内的激烈讨论。一些专家认为,如果Claude3.5Sonnet能够在较少的参数下有效执行,这将突显Anthropic的技术实力。相反,其他分析师则建议某些参数估计可能与模型定价结构相关。
有趣的是,尽管论文对多个主流模型进行了参数估算,但显著地省略了关于谷歌Gemini的具体细节。分析师推测,这一省略可能源于Gemini使用TPU而非Nvidia GPU,这使得基于令牌生成速度进行准确估算更加复杂。
随着OpenAI日益淡化其对开源倡议的承诺,模型参数等核心信息的披露仍然是业内关注的焦点。这一意外泄露促使重新讨论AI模型架构、技术发展路径和行业竞争。
参考文献:
- 微软最近的论文揭示了包括OpenAI和Anthropic在内的各种AI模型的参数大小。
- 该论文介绍了一个用于医疗AI的基准测试MEDEC,使用临床记录进行评估。
- 参数披露中的差异可能表明关于模型性能和架构效率的持续争论。