Meta AI发布MobileLLM-R1:轻量级边缘AI模型
Meta AI推出面向边缘推理的MobileLLM-R1
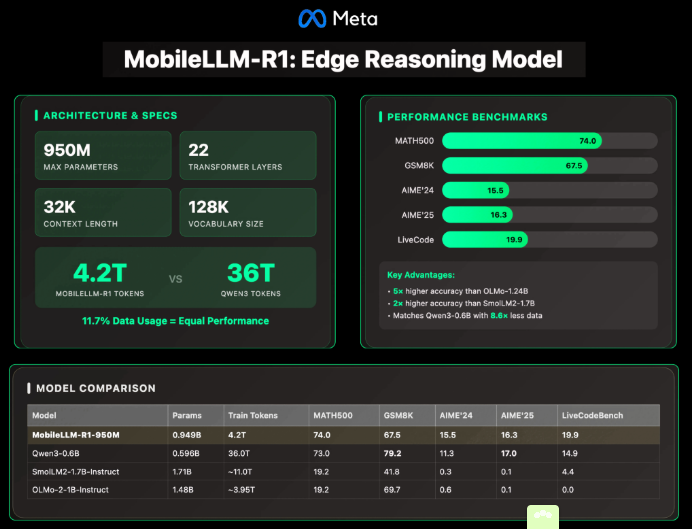
Meta AI正式发布MobileLLM-R1系列轻量级边缘推理模型,现已在Hugging Face平台上线。这些模型的参数量介于1.4亿至9.5亿之间,专为高效数学运算、编程和科学推理任务优化,同时以不足10亿参数的规模保持高性能。
架构创新
该系列的旗舰模型MobileLLM-R1-950M包含多项架构优化:
- 22层Transformer结构,配备24个注意力头和6组KV头
- 1536维嵌入层及6144维隐藏层
- 分组查询注意力(GQA)机制降低计算与内存需求
- 块级权重共享技术减少参数且不增加延迟
- SwiGLU激活函数增强小模型表征能力
该模型支持4K上下文长度,经训练后可扩展至32K。
训练效率突破
MobileLLM-R1展现出卓越的训练效率:
- 仅使用约4.2万亿token进行训练
- 数据消耗仅为Qwen3的0.6B模型的11.7%(后者消耗36万亿token)
- 在减少训练数据情况下仍达到或超越Qwen3的准确率
该模型通过数学、编程和推理任务的监督数据集微调,显著降低了训练成本与资源需求。
基准测试表现
全面测试显示MobileLLM-R1-950M表现优异:
- MATH500数据集:
- 准确率比OLMo-1.24B高约5倍
- 比SmolLM2-1.7B高约2倍
- 在以下领域匹配或超越Qwen3-0.6B:
- GSM8K(推理)
- AIME(数学)
- LiveCodeBench(编程)
这些成就尤其值得关注,因为该模型的token消耗量远低于竞争对手。
局限性与注意事项
MobileLLM-R1的专业化设计存在特定权衡:
- 在以下领域表现逊于更大模型:
- 通用对话
- 常识推理
- 创意任务
- Meta的FAIR NC(非商业)许可证限制其生产环境使用
- 扩展至32K上下文会增加推理时的键值缓存和内存需求
行业影响
MobileLLM-R1的发布标志着行业向小型专业化模型的趋势发展——这类模型无需巨额训练预算即可提供有竞争力的推理能力。它们为数学、编程和科学领域的边缘设备部署大语言模型设立了新标准。
项目地址:https://huggingface.co/facebook/MobileLLM-R1-950M
核心要点:
✅ 新模型发布: Meta AI的MobileLLM-R1系列提供参数量1.4亿至9.5亿的轻量级边缘推理方案。 ✅ 训练高效性: 仅用典型训练数据的~11.7%即实现更优性能。 ✅ 性能优势: 在数学与编程基准测试中超越更大开源模型。