美团新AI模型以智能参数技巧展现强劲实力
美团重新定义高效AI模型的规则

在AI领域,更大并不总是意味着更好。当大多数团队还在不断堆叠模型中的'专家'时,美团的LongCat团队另辟蹊径。他们最新发布的LongCat-Flash-Lite证明:智能化的参数运用可以胜过暴力缩放。
嵌入层的突破
传统MoE(专家混合)架构随着规模扩大会遭遇收益递减。但美团的方案独树一帜:通过战略性强化嵌入层而非单纯增加专家数量,他们打造的模型每个任务仅激活29至45亿参数——尽管总参数量高达685亿。
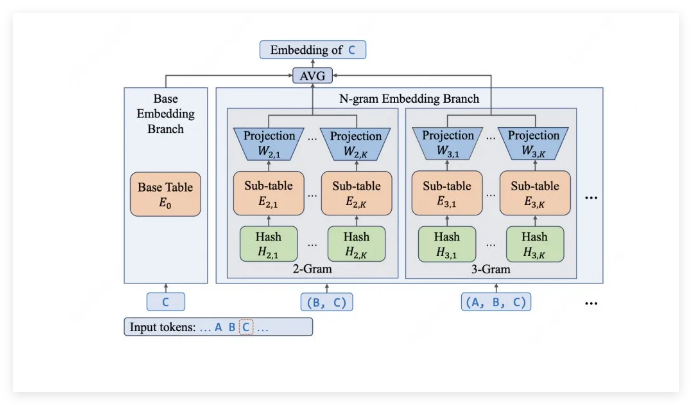
秘诀何在?采用N-gram嵌入系统精准捕捉局部模式。需要理解编程指令或技术术语?该模型识别这些模式就像资深程序员熟悉语法一样游刃有余。
幕后工程魔法
将理论优势转化为实际速度依赖三项精妙优化:
- 智能参数分配: 近半数模型容量集中于嵌入层,采用高效的O(1)查询替代昂贵计算
- 定制硬件技巧: 团队开发了专用缓存(可视为超级N-gram内存)并融合关键操作以削减处理延迟
- 预测协同: 通过将推测解码与独特架构结合,在处理超大256K上下文窗口时仍能达到每秒500-700token的惊人速度
令人瞩目的性能表现
数据说明一切:
- 编码能力: SWE-Bench得分54.4%,终端命令测试表现优异(TerminalBench得分33.75)
- 智能体优势: 在电信、零售和航空场景的专业基准测试中拔得头筹
- 通用智能: MMLU测试与Gemini2.5Flash-Lite持平(85.52分),同时在高阶数学领域毫不逊色
最精彩的部分?美团公开了所有资源——模型权重、技术深度解析甚至定制推理引擎(SGLang-FluentLLM)。开发者可通过LongCat API平台每日获取5000万免费token来体验这一创新方案。
核心要点:
- 突破传统MoE扩展模式,通过优化嵌入层而非单纯增加专家数量
- 每个任务仅激活45亿参数即可实现大模型性能
- 专用缓存与内核融合带来超凡速度(500+token/秒)
- 开源版本包含权重、技术报告和推理引擎