IBM Granite 4.0语音模型:更小巧、更智能、更迅捷
IBM以紧凑型语音AI模型树立新标杆
IBM推出Granite 4.0 1B Speech语音识别技术最新突破,这一举措或将重塑企业处理多语言通信的方式。此次发布的特别之处在于:这家科技巨头成功在缩小模型体积的同时提升了性能——这在AI领域实属罕见。
更精简的设计,更卓越的性能
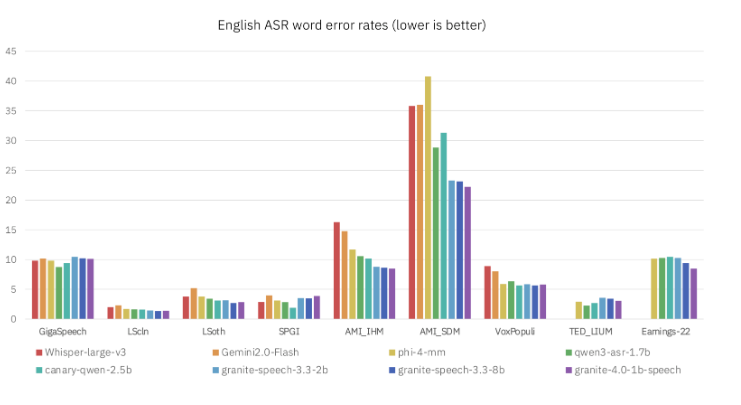
新版模型的参数量减半,却在关键指标上实现显著提升。想象一下用更少资源获得更好结果——这正是IBM在此实现的突破。该模型现支持日语语音识别,并引入关键词偏置调整等智能功能。
英语转录准确率提升尤为亮眼。「我们致力于让每个参数物尽其用,」项目首席研究员Sarah Chen博士解释道,「最终得到的不仅是一个表现更好的模型——它的运行效率也更高。」
工作原理:两阶段处理架构
Granite的创新架构蕴藏其成功秘诀:
- 首先进行音频到文本的转换
- 文本随后流经IBM专用的Granite语言模型
这种模块化设置赋予开发者根据需求定制系统的灵活性。仅需转录功能?使用第一阶段即可。需要完整翻译?启用两个组件。
目前支持六大主要语言(英语、法语、德语、西班牙语、葡萄牙语和日语),该模型在处理英译汉任务时表现尤为出色。
令人瞩目的性能表现
数据讲述着惊艳的故事:
- 高居OpenASR排行榜首位
- 平均词错误率仅5.52%
- 内存占用和处理延迟显著降低
「最令人兴奋的是看到企业级AI变得触手可及,」技术分析师Mark Williams指出,「借助此类能在边缘设备流畅运行的模型,我们正在消除技术采用壁垒。」
IBM已依据Apache 2.0许可证开源Granite,欢迎开发者使用Transformers或vLLM等框架进行本地部署实验。
核心亮点:
- 较前代体积缩小50%且准确率提升
- 支持六种语言,新增日语能力
- 创新的两阶段处理实现灵活部署
- 词错误率低至5.52%创纪录
- 通过Hugging Face提供开源版本