Google DeepMind新技术让AI在硬件故障时仍能持续学习
Google DeepMind在容错AI训练领域的突破
想象一下,如果一位音乐家晕倒,整个音乐会就会停止。这基本上就是当今大多数AI训练的运作方式——直到现在。Google DeepMind的新Decoupled DiLoCo架构通过创建工程师所称的"计算孤岛"来改变游戏规则,这些孤岛可以独立运行。
当前系统的问题
传统的AI训练方法要求所有硬件组件完美同步。每个处理器都必须等待其他所有处理器完成计算才能继续前进——这是一种数字版的"匆忙等待"。当哪怕一个芯片出现故障时(在拥有数千个组件的大型系统中,故障会不断发生),一切都会陷入停滞。
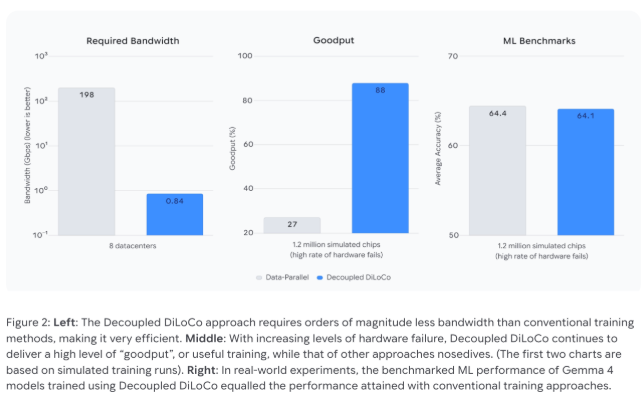
DiLoCo如何改变现状
该系统将处理器组织成称为"学习单元"的自包含集群,这些单元像微型训练中心一样运作。每个单元可以完成多轮计算,然后将汇总的更新发送给中央协调器。这种异步方法意味着:
- 硬件故障时不再有连锁反应
- 带宽需求大幅减少(从198 Gbps降至不到1 Gbps)
- 新旧芯片可以协同工作,延长设备寿命
"这就像从接力赛切换到平行停车一样,"一位熟悉该项目的工程师解释道。"每辆车都能在不阻挡其他车的情况下找到自己的位置。"
实际性能表现
数据说明了一切:
| 指标 | 传统方法 | DiLoCo | 改进幅度 |
|---|
该系统甚至在混沌工程测试中表现出卓越的韧性——当所有学习单元暂时失效时仍能继续运行,并在恢复后顺利重新整合它们。
这项技术为何超越科技圈的重要性
这一突破可能对各行业产生连锁反应:
- 环境影响:延长硬件寿命减少电子垃圾
- 全球协作:使跨大洲的分布式训练成为可能
- 成本节约:更少的停机时间意味着更快的模型开发周期
随着AI模型变得日益庞大(有些现在需要连续数月的训练),像DiLoCo这样的解决方案可能成为必要的基础设施,而非可有可无的升级。
关键点:
- 🛡️ 容错设计确保硬件故障时训练不中断
- 🌐 带宽效率实现实用的全球协作
- ♻️ 硬件灵活性允许新旧设备混用
- ⚡ 自愈能力自动从中断中恢复


