Google DeepMind的D4RT赋予AI穿越时间的视觉能力
Google DeepMind突破性实现四维AI视觉

多年来,计算机科学家一直致力于让机器获得真正的视觉理解能力——那种不仅能让人类看到当下,还能直观把握场景随时间演变的能力。如今,Google DeepMind的新模型D4RT或许终于能弥合这一差距。
从平面图像到鲜活世界
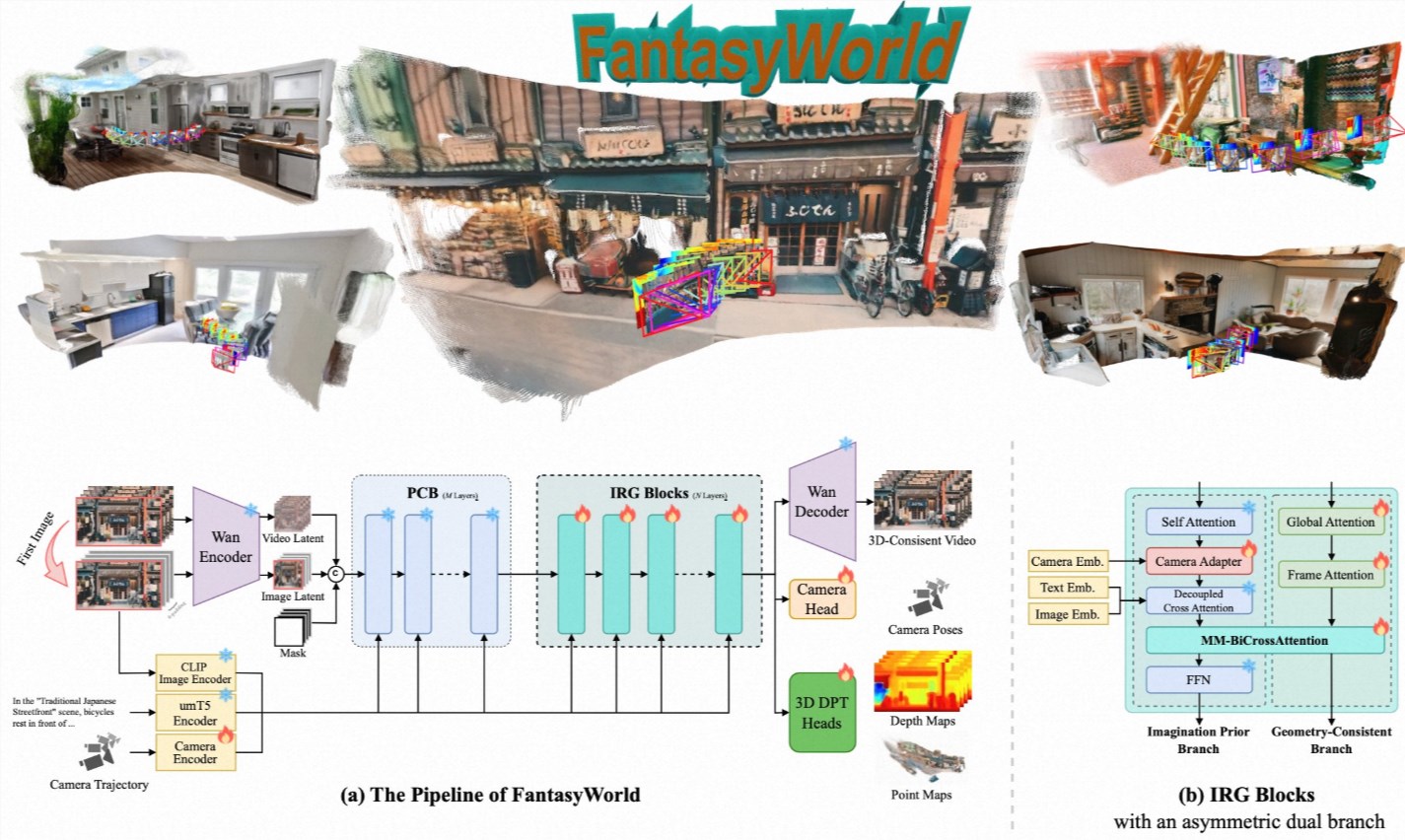
这一突破源于将时间视为与长、宽、高同等重要的维度。"我们不再要求AI从碎片中拼凑理解,"首席研究员Elena Petrov博士解释道,"D4RT学习整体地观察世界——过去、现在和可能的未来。"
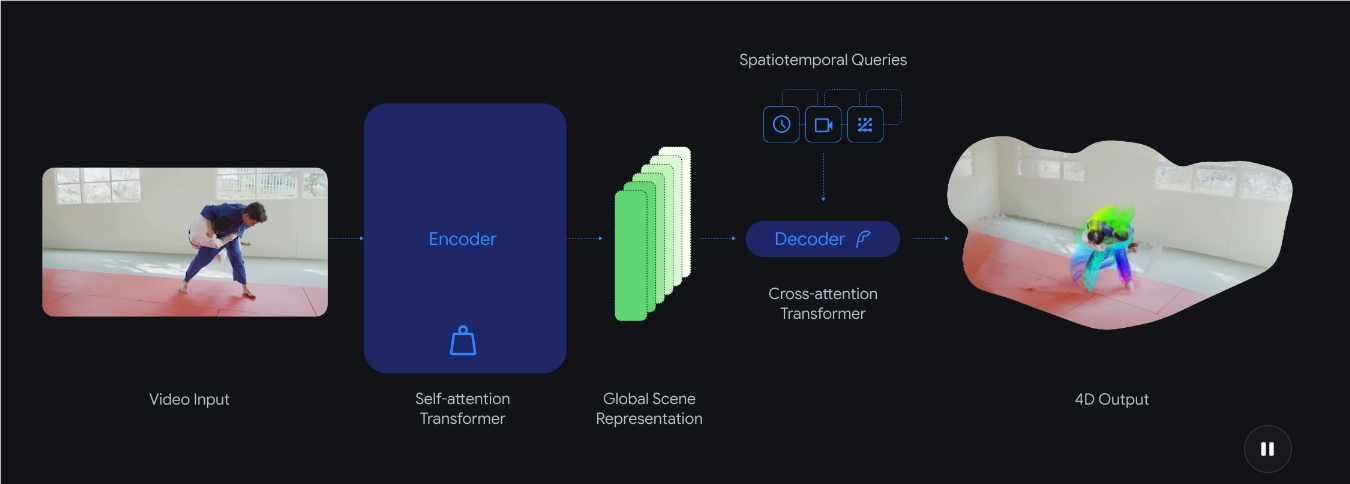
传统系统需要单独的模型进行深度计算、运动追踪和透视分析——就像蒙着眼睛拼拼图。D4RT的优雅解决方案是什么?将所有问题都框定为一个核心问题:"这个像素在时空中的确切位置是哪里?"
闪电般的空间推理能力
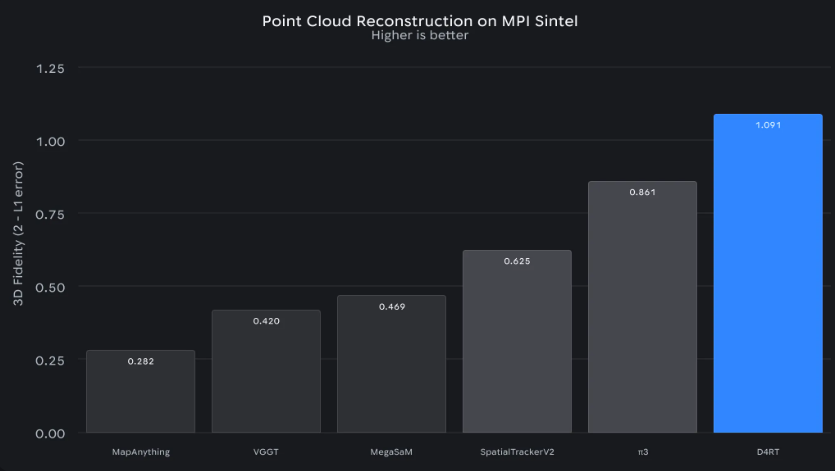
数据说明一切:
- 处理一分钟视频仅需5秒,而之前系统需要10分钟
- 即使在遮挡或镜头移动时也能保持物体追踪
- 无需迭代优化即可即时重建3D环境
"这不仅仅是更快,"机器人专家Jamal Chen指出,"这可能让自主系统真正实现预测而非被动反应。"
实用的魔法
应用场景读起来像是科幻成真:
- 机器人技术:机械臂能在碰撞发生前调整轨迹
- AR/VR:眼镜可在移动表面上投射稳定的全息影像
- 智慧城市:交通系统可预测行人流动
- 科学研究:逐帧重建微观过程
正如Petrov所说:"我们不再教算法看静态快照了。我们在帮助它们感知动态流。"
关键要点:
- 统一架构:将空间和时间处理结合在一个模型中
- 实时处理:视频分析速度比前代快达300倍
- 持续追踪:即使遇到障碍也能保持物体感知
- 广泛应用:从机器人技术到增强现实界面