告别模糊的框框!SegVG 让 AI 拥有像素级精准度
告别模糊的框框!SegVG 让 AI 拥有像素级精准度
在 AI 视觉 领域,目标定位一直就像是在戴着一副起雾的眼镜。没错,传统算法可以在物体周围加上一些粗略的“边界框”,但这就像在描述你最好的朋友时只说:“嗯,他们大概有 6 英尺高,呃……有点宽?”这样并不太有帮助,对吧?
好吧,现在是 2024 年,我们已经不再用那些过时的把戏了!来自 伊利诺伊理工学院、思科研究院 和 中佛罗里达大学 的一群天才们创造了一项革命性的技术。认识一下 SegVG,一个定位框架,它将把 AI 的近视问题解决干净,让它拥有像素级的清晰度!
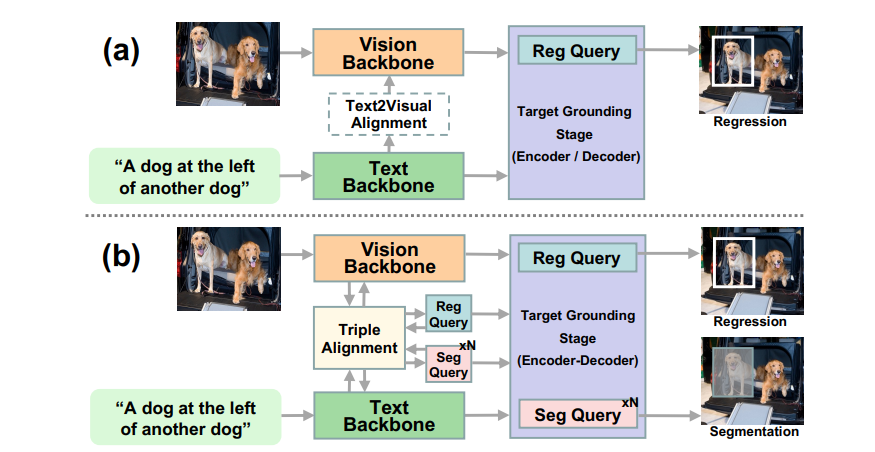
SegVG:让 AI 进入高清时代!
那么,SegVG 到底特别在哪里?传统的 AI 算法只能处理边界框,这基本上相当于让 AI 看一个模糊的影子,然后期望它能搞清楚情况。而 SegVG 则像给 AI 戴上了清眼镜赋予了它能看到每一个像素的能力。没错,不再有任何猜测游戏!
与其只是把一个框扔到物体周围,SegVG 将那个框的粗略信息转换为 分割信号。想象一下,从一个 8 位像素的游戏升级到 4K 超高清。AI 的视觉现在异常清晰,甚至可以捕捉到最微小的细节。
幕后的魔法:多任务解码器
现在,让我们谈谈技术问题。SegVG 的核心是一种叫做 “多层多任务编码器-解码器” 的东西。听起来很复杂,但简单来说——可以把它想象成一个超级显微镜。这个设备可以使用不同的‘镜头’来处理 边界框回归 和 分割 任务,像是一双紧密合作的眼睛,确保没有任何东西被忽略。
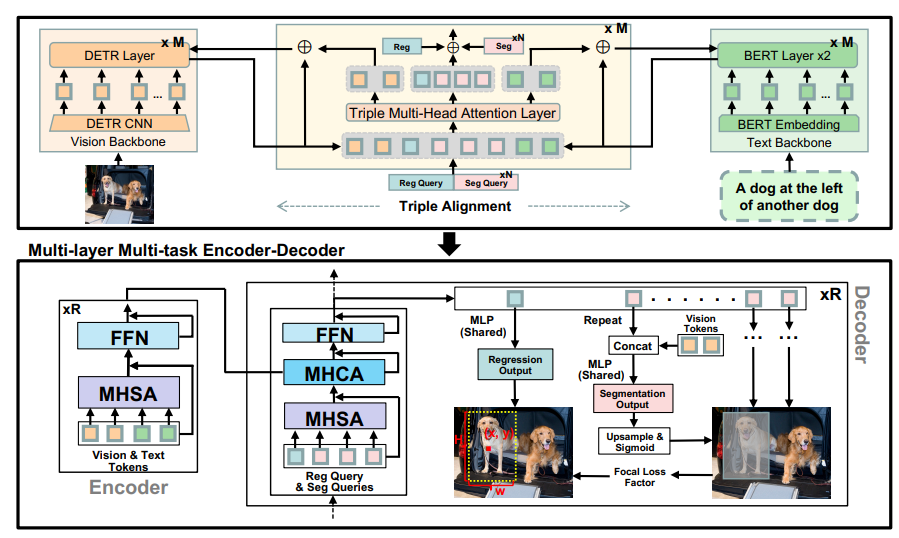
但等等,更多精彩还在后面!SegVG 配备了一个 三重对齐模块。简单来说:它就像是 AI 的翻译器,教会它理解预训练参数和查询嵌入的‘语言’。通过这种 三重注意机制,SegVG 将 AI 的查询、文本和视觉信息整合到一个清晰的通道中。这就像终于让所有人用同一个调子唱歌!
它的效果如何?
你可能在想,“听起来不错,但它真的有效吗?” 哦,它的效。SegVG 的专家们在五个流行的数据集上对其进行了测试,包括臭名昭著的棘手数据集 RefCOCO+ 和 RefCOCOg。结果呢?SegVG 碾压了它们,在算法领域大放异彩!
不仅如此,SegVG 还可以给出其预测的 置信度分数。因此,如果 AI 对自己的判断有些“不确定”,它会告诉你。这在 医学影像 等领域尤为重要,因为错误的判断可能会带来灾难性后果。如果 AI 的信心水平下降,那就是人类介入的时候了。
开源的魅力
这里有一个额外的好消息:SegVG 是开源的。这意味着世界各地的开发人员和研究人员都可以投入其中,进行调整,并进一步推动 AI 视觉技术的边界。合作,朋友们——这就是未来!
想要更仔细了解?点击这里查看论文 here 并在 GitHub 上查看代码 here。
摘要
传统的 AI 算法依赖过时的模糊边界框进行物体识别。
SegVG 提供像素级的精确度,让 AI 拥有高清视觉能力。
该框架使用多层、多任务编码器-解码器来提高定位的精准度。
它还包括一个三重对齐模块,以改善 AI 对预训练参数和查询嵌入的理解。
SegVG 是开源的,鼓励社区合作进一步推动 AI 视觉技术的发展。